为了刺激自己学习和使用superset的欲望,可以点击这里,先看下github上的效果图,同时,个人感觉SQL Lab也是一个特别赞的功能。
下面从安装开始介绍superset。
需要注意的是:superset是在Python2.7和Python3.4下测试的,Airbnb生产环境使用的Python版本是2.7.x,并且Airbnb不打算支持Python2.6。
Python的安装步骤,在这里就不做说明了,因为Centos7自带的Python已经是2.7.x版本了,所以无需额外安装。可以通过python -V查看Python的版本。
本文是在以下环境下测试的:
curl https://bootstrap.pypa.io/ez_setup.py | sudo python -
安装完成之后,验证一下:
[vagrant@hadoop-slave-1 ~]$ easy_install --version setuptools 33.1.1 from /usr/lib/python2.7/site-packages/setuptools-33.1.1-py2.7.egg (Python 2.7)
sudo yum install -y gcc-c++ python-devel libffi libffi-devel openssl openssl-devel cyrus-sasl-lib cyrus-sasl-devel cyrus-sasl gettext
sudo easy_install flask
下载:
curl -o numpy-1.7.0.tar.gz https://pypi.python.org/packages/e7/b8/0eec6203c783047760db02f86791814c860397a7c79c444ddabc8a2f1c69/numpy-1.7.0.tar.gz#md5=4fa54e40b6a243416f0248123b6ec332
解压:
tar zxf numpy-1.7.0.tar.gz
安装:
cd numpy-1.7.0/ sudo python setup.py install
下载:
curl -o pandas-0.19.2.tar.gz https://pypi.python.org/packages/08/9d/31ec596099f14528fc6ad39428248ac5360f0bb5205a3ee79a5d1cf260fb/pandas-0.19.2.tar.gz#md5=26df3ef7cd5686fa284321f4f48b38cd
解压:
tar zxf pandas-0.19.2.tar.gz
安装:
cd pandas-0.19.2/ sudo python setup.py install
下载
curl -o superset-0.18.2.tar.gz https://pypi.python.org/packages/56/53/83d8e2d6cd2c36d0318f82b7f611a07e534e7fb0afe3dd5424a57f114082/superset-0.18.2.tar.gz#md5=27ea370cc453a1937e9209778fc15ab0
解压:
tar zxf superset-0.18.2.tar.gz
安装:
cd superset-0.18.2/ sudo python setup.py install
至此,superset就安装完毕了,下面开始superset的入门教程。
1,创建管理员账户
fabmanager create-admin --app superset
在输入用户名,姓名,邮箱,密码之后,fabmanager会在用户的主目录下创建.superset隐藏目录,并在该目录下创建一个sqlite3数据库。执行下面的命令可以看到上一步创建的用户被保存到了ab_user表中:
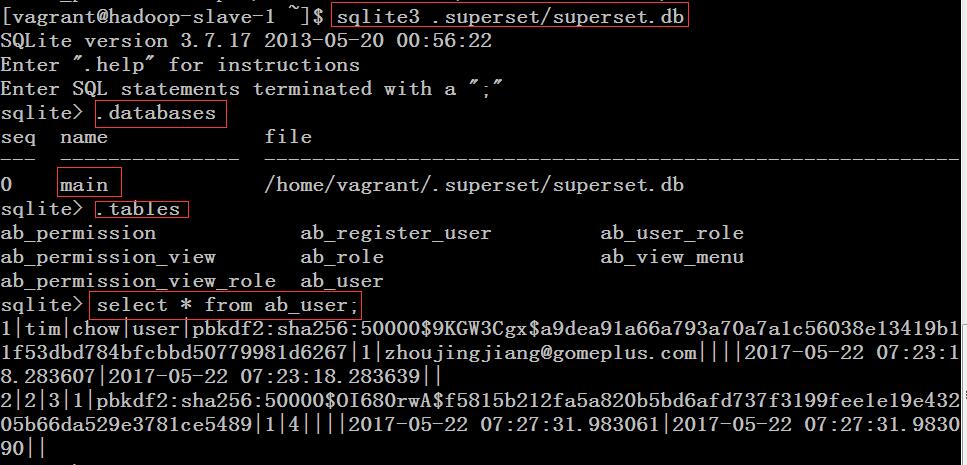
2,初始化数据库
superset db upgrade
3,加载一些测试数据
superset load_examples
4,创建默认的角色和权限
superset init
5,启动web服务器
superset runserver
web服务器的默认端口是8088,可以通过-p选项绑定其他的端口;也可以通过-d选项启动一个用于开发的服务器。
需要注意的是:
superset默认的应用服务器是gunicorn,但是gunicorn是无法在windows上工作的,所以在windows上只能使用用于开发的服务器。
启动web服务器之后,就可以使用浏览器访问superset了。
可以通过创建一个叫做superset_config.py的模块,并将它放到PYTHONPATH下的方式,配置superset。下面是一个示例:
#--------------------------------------------------------- # Superset specific config #--------------------------------------------------------- ROW_LIMIT = 5000 SUPERSET_WORKERS = 4 SUPERSET_WEBSERVER_PORT = 8088 #--------------------------------------------------------- #--------------------------------------------------------- # Flask App Builder configuration #--------------------------------------------------------- # Your App secret key SECRET_KEY = '\2\1thisismyscretkey\1\2\e\y\y\h' # The SQLAlchemy connection string to your database backend # This connection defines the path to the database that stores your # superset metadata (slices, connections, tables, dashboards, ...). # Note that the connection information to connect to the datasources # you want to explore are managed directly in the web UI SQLALCHEMY_DATABASE_URI = 'sqlite:////path/to/superset.db' # Flask-WTF flag for CSRF CSRF_ENABLED = True # Set this API key to enable Mapbox visualizations MAPBOX_API_KEY = ''
在这个配置模块中,也可以定义被Flask App Builder(superset所使用的web框架)使用的参数,关于这部分配置,请查看这里。
其中有两个需要改变的参数:
SQLALCHEMY_DATABASE_URI~/.superset/superset.db,该参数用来指定 保存superset元数据(比如slices、connections、tables、dashboards等)的数据库 的Sqlalchemy连接字符串(要搜索的数据源的连接信息是由web UI直接管理的)
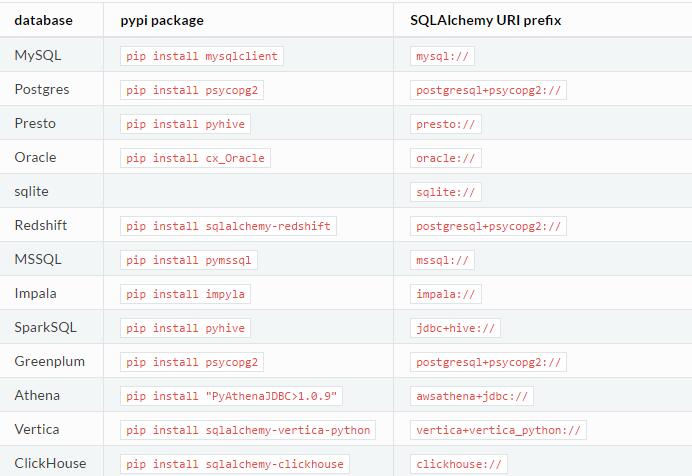
SECRET_KEY 默认情况下,superset是把元数据保存到sqlite中的,所以除了sqlite之外,superset不依赖任何数据库。如果想要把superset元数据保存到其它的数据中,那么需要安装相应的驱动以及给SQLALCHEMY_DATABASE_URI参数指定一个正确的值。下面是一些推荐使用的数据库、数据库驱动以及对应的SQLAlchemy URI前缀:
superset使用Flask-Cache来缓存数据。在superset_config.py中,可以通过CACHE_CONFIG参数配置缓存所使用的后端。
Flask-Cache支持多种缓存后端,比如Redis、Memcached、SimpleCache(in-memory)、local filesystem。以redis为例,首先应该安装Python的redis驱动:
sudo easy_install redis
然后在superset_config.py中增加如下的配置:
CACHE_CONFIG = {
"CACHE_TYPE": "redis",
"CACHE_REDIS_URL": "redis://[redis:<密码>]@:/",
"CACHE_KEY_PREFIX": "A CACHE_KEY_PREFIX"
}
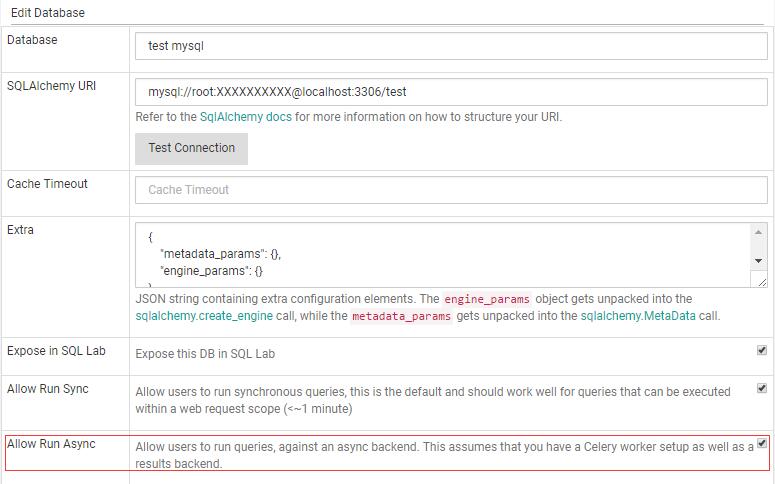
在superset中可以通过SQLAchemy暴漏的参数调整数据库连接信息,在Database编辑页面,可以看到一个Extra域(值是一个Json串):

在这个Json串中可以包含额外的配置选项。其中engine_params所指定的参数会传递给sqlalchemy.create_engine调用;metadata_params所指定的参数会传递给sqlalchemy.MetaData调用。更多详细信息,可以阅读SQLAlchemy的文档。
superset允许自定义中间件,方法是:
superset_config.py中增加ADDITIONAL_MIDDLEWARE参数,该参数的值是一个 中间件类 的列表
比如:
# superset_config.py
# other configuration...
class TestMiddleware(object):
def __init__(self, app):
self.app = app
def __call__(self, environ, start_response):
print("test middleware")
return self.app(environ, start_response)
ADDITIONAL_MIDDLEWARE = [TestMiddleware]
sudo easy_install --upgrade superset superset db upgrade superset init
SQL Lab是一个非常强大的SQL IDE,它可以和所有与SQLAlchemy兼容的数据库一起使用。默认情况下,查询是在web请求的作用域中执行的,因此当web请求超时的时候,查询也会超时。
为了支持运行时间超过web请求的超时时间的查询,superset支持异步查询,配置异步查询的方式如下:
Allow Run Async域
superset_config.py模块中,通过CELERY_CONFIG配置celery的broker和result backend,注意:worker和web服务进程应该使用相同的配置
superset worker命令,启动一个或多个superset worker(本质上就是celery worker)
superset_config.py配置模块中给RESULTS_BACKEND键指定为werkzeug.contrib.cache.BaseCache的一个派生类实例。可以使用自带的Redis、Memcache、S3、内存、文件系统cache实现,也可以自己编写cache实现
# superset_config.py
# other configurations ...
class CeleryConfig(object):
BROKER_URL = 'redis://localhost:6379/0'
CELERY_IMPORTS = ('superset.sql_lab', )
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
CELERY_CONFIG = CeleryConfig
from werkzeug.contrib.cache import RedisCache
RESULTS_BACKEND = RedisCache(
host='192.168.30.2', port=6379, db=3,
key_prefix="superset_results:")
```
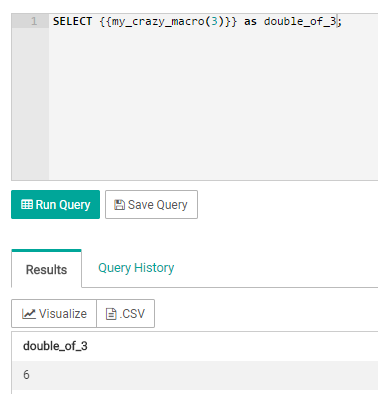
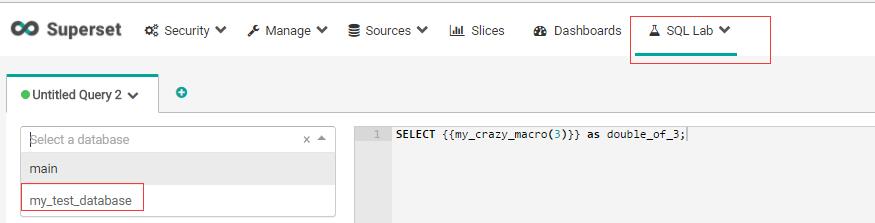
SQL Lab在查询的时候,也支持Jinja模版,可以通过superset配置文件中的`JINJA_CONTEXT_ADDONS`参数配置默认的Jinja上下文。比如:
```
JINJA_CONTEXT_ADDONS = {
'my_crazy_macro': lambda x: x*2,
}
登陆之后点击:
然后点击“+”,进入到Database view页面:
在database view页面,填写数据库的名字以及SQLAlchemy连接字符串,想要了解更多关于SQLAlchemy连接字符串,请点击这个链接:
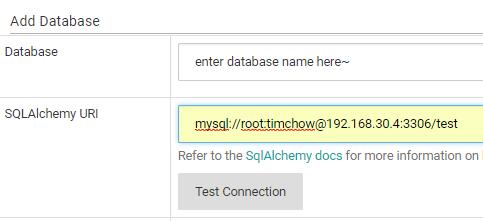
然后点击“Test Connection”,如果运行superset服务的实例能够连接到数据库,会弹出类似下面的提示信息:

同时要注意以下几项:
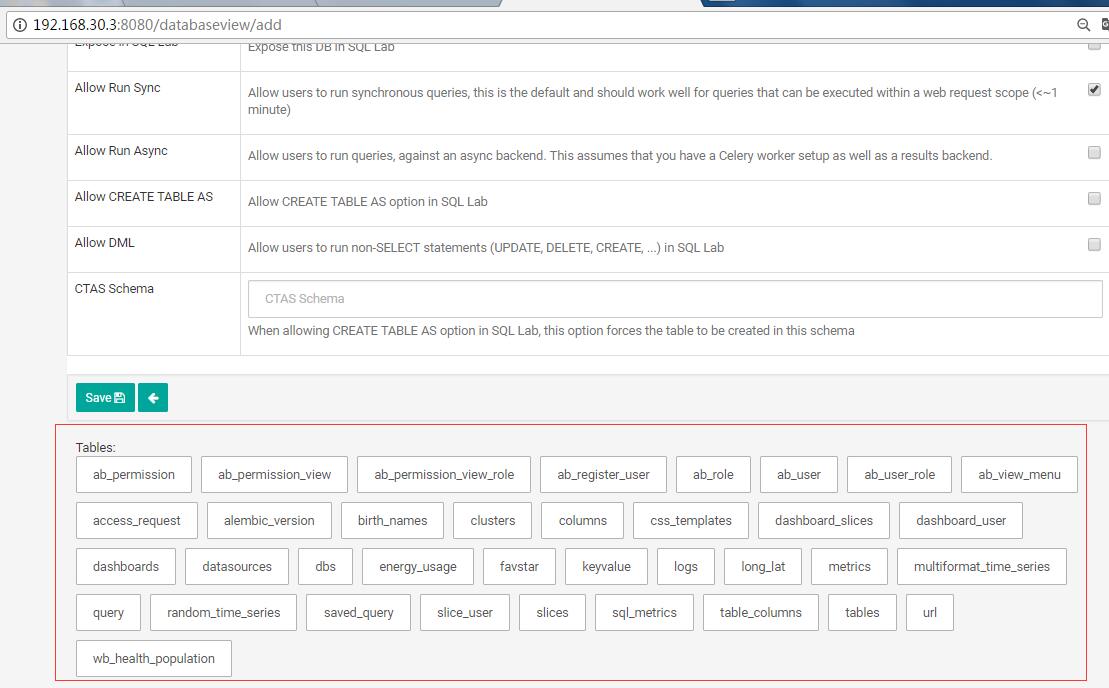

保存之后,在SQL Lab中就可以看到这个数据库了:

最后点击“Save”按钮,这个数据库就建立完成了。
首先,在上一步添加的数据库中,创建一张新表:
CREATE TABLE `grade_test` ( `course_id` int(10) unsigned NOT NULL, `student_id` int(10) unsigned NOT NULL, `grade` int(10) unsigned NOT NULL DEFAULT '0', `last_update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `course_name` varchar(100) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8
然后,插入一些测试数据:
insert into grade_test(course_id, student_id, grade, course_name) values(1,1,80,"english"),(1,2,85,"english"),(2,1,90,"math"),(2,2,70,"math"),(1,3,99,"english"),(2,3,88,"math");
接下来开始添加新的表:
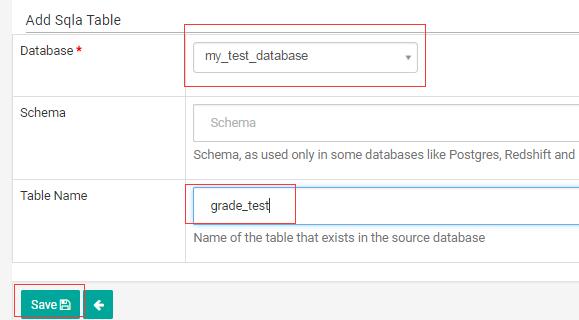
保存之后,重定向到的页面顶部会有一条提示信息:

然后进入到“Table Model View”页面,点击新添加的表的表名前面的“Edit record”:
在结果页面上,点击“List Table Column”标签:
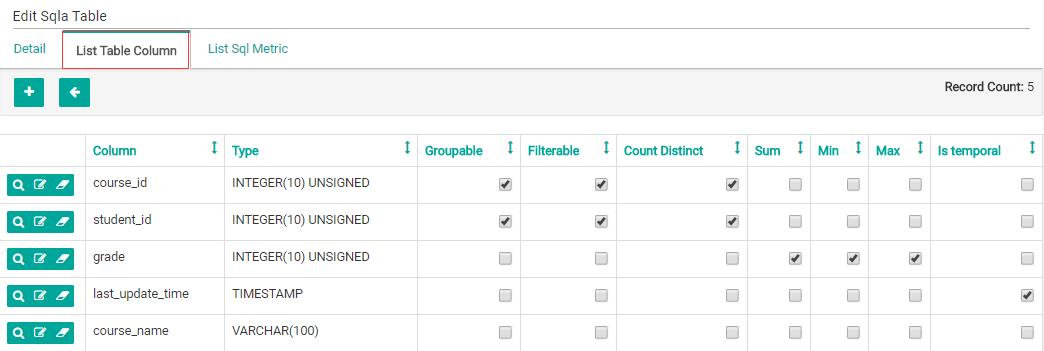
接下来,就可以定义对表中指定的列的使用方式了:
首先,进入到“Table Model View”:
然后点击表名:
默认情况下,展现的是Table View,并且默认的查询是获取表中的所有的记录数:
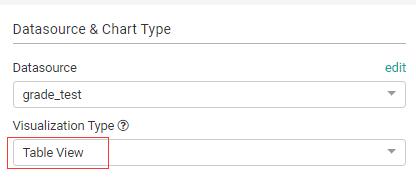
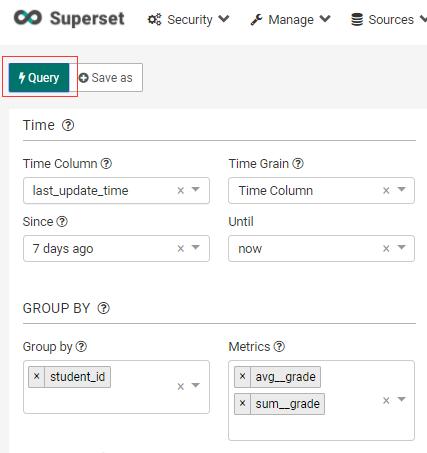
接下来看“Time”区:
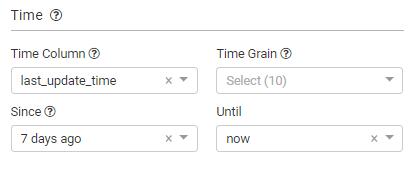
“Time”区的下面是“Group By”区:
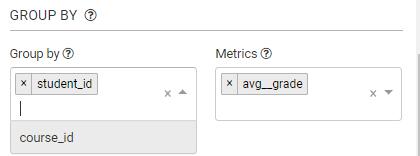
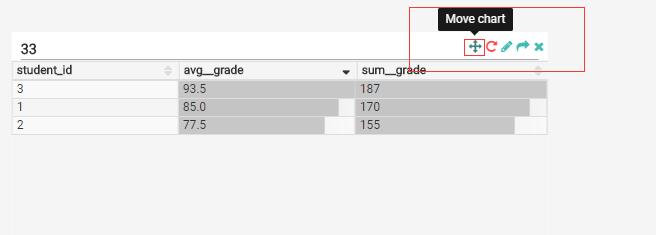
比如,想要求每个学生的平均成绩和成绩总和:
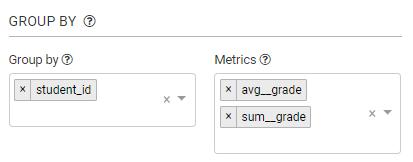
然后点击,左上角的Query,就可以在右侧看到结果了:

下面看一些其它有趣的功能:
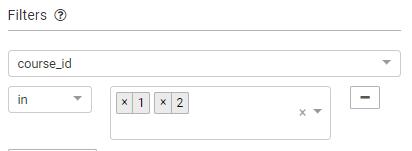
点击页面右上角的Query按钮:
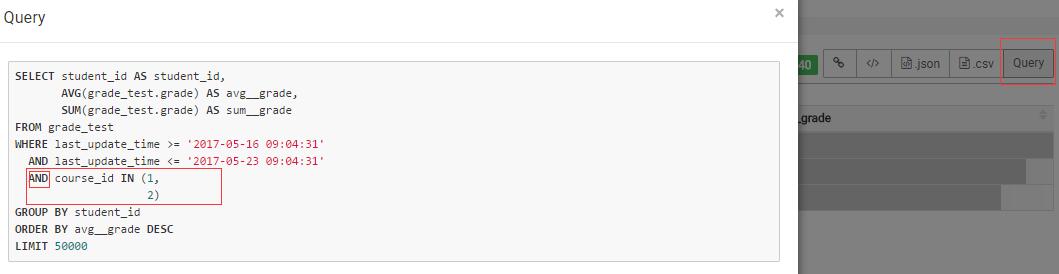
Filters其实是以AND的方式加到where语句的条件中了
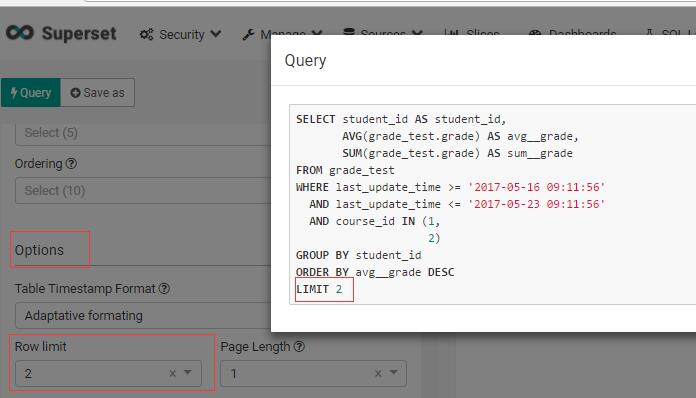
Superset支持很多表格类型,具体可以看官网提供的“画廊”。
一个被保存的查询叫做slice。点解Query按钮右侧的Save as按钮就可以创建一个slice:
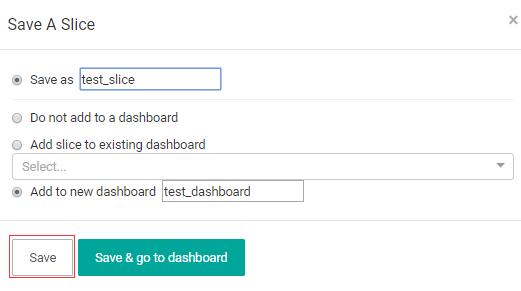
点击Save as,在Save as窗口填写slice的名字,同时也可以将slice添加到一个新创建的dashboard中,或已经已经存在的dashboard中,当然也可以不添加到任何dashboard中(所以说,一个dashboard可以一起展示0个或多个slice):
接下来,我们就可以在slice和dashboard中分别看到刚才新建的slice和dashboard:
进入到刚才新建的dashboard,可以通过拖拽表格的右下角,放大和缩小表格:
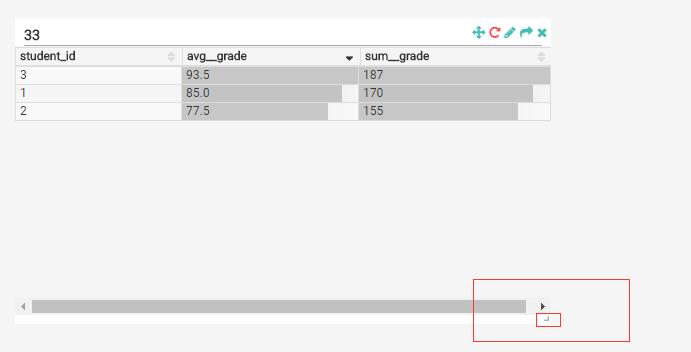
还可以通过右上角的 Move Chart来移动表格:
修改dashboard之后,需要点击保存按钮进行保存:
在 superset入门教程 小节中,已经介绍过,可以通过superset load_examples命令导入一些测试数据,其中包含若干slice和dashboard,因此可以通过研究这些slice,来学习画出比Table View更“漂亮”的表格。