multi-mechanize是一个开源的性能和负载测试框架,它并发的运行python脚本来生成一个远程站点或服务的负载。
multi-mechanize通常用于web性能和扩展性测试,但是也能用于使用python来生成任何远程的可访问的api的负载。
测试输出报告既能存储为HTML,也可以存储为JMeter兼容的XML。
multi-mechanize需要python2.6或2.7
pip install -U multi-mechanize
或者是从pypi下载源代码,解压缩,然后运行:
python setup.py install
创建项目
用multimech-newproject命令创建一个新的测试项目:
multimech-newproject my_project
每一个项目包含下面的文件和目录:
config.cfg:配置文件,在这里设置测试选项。
test_scripts/:放置虚拟用户脚本的目录,在这里放置测试脚本。
results/:存储结果的目录,会为每次测试创建一个包含结果报告的时间戳目录。
运行项目
用multimech-run命令运行一个测试项目:
multimech-run my_project
可能会报错:
Traceback (most recent call last): File "/usr/bin/multimech-run", line 11, insys.exit(main()) File "/usr/lib/python2.6/site-packages/multimechanize/utilities/run.py", line 64, in main run_test() File "/usr/lib/python2.6/site-packages/multimechanize/utilities/run.py", line 131, in run_test results.output_results(output_dir, 'results.csv', run_time, rampup, results_ts_interval, user_group_configs, xml_report) File "/usr/lib/python2.6/site-packages/multimechanize/results.py", line 65, in output_results graph.resp_graph_raw(trans_timer_points, 'All_Transactions_response_times.png', results_dir) File "/usr/lib/python2.6/site-packages/multimechanize/graph.py", line 23, in resp_graph_raw fig = figure(figsize=(8, 3.3)) # image dimensions NameError: global name 'figure' is not defined
这是因为没有安装Matplotlib包,无法绘制结果图。
安装Matplotlib包:
yum install -y python-matplotlib
配置文件(config.cfg)
每个项目都包含一个用于定义测试设置的config.cfg文件。
配置文件包含[global]区和[user_group-*]区。
全部配置
这是一个简单的config.cfg文件,它展示了所有可能的选项,定义了两个虚拟用户组:
[global] run_time = 300 rampup = 300 results_ts_interval = 30progress_bar = onconsole_logging = off xml_report = off results_database = sqlite:///my_project/results.db post_run_script = python my_project/foo.py [user_group-1]threads = 30script = vu_script1.py [user_group-2] threads = 30script = vu_script2.py
下面是global配置区域中可用的设置/选项:
run_time:测试的执行时间(单位是秒)[必须存在]
rampup:用户提速的时间,也就是在多长时间内创建完配置中配置的线程数(单位是秒)[必须存在]results_ts_interval:用于结果分析的时间序列间隔(单位是秒)[必须存在]progress_bar:测试运行期间打开或关闭控制台进度条[可选选项,默认是on]console_logging:是否向标准输出中打印日志[可选选项,默认是off]xml_report:是否生成XML报告[可选选项,默认是off]results_database:保存结果的数据库连接串[可选选项]post_run_script:测试完成后调用的脚本[可选选项]下面是每一个[user_group-*]配置区域中可用的设置/选项:
threads:每一个虚拟用户的线程数量
script:要运行的虚拟用户测试脚本
虚拟用户脚本编写
脚本使用python编写
基础
每一个脚本必须实现一个Transaction()类,这个类必须实现run()方法。
因此一个基本的测试脚本包含:
class Transaction(object):
def run(self):
# do something here
return
在测试运行期间,Transaction()类被实例化一次,它的run()方法会在一个循环里被重复的调用。
class Transaction(object):
def __init__(self): # do per-user user setup here # this gets called once on user creation return
def run(self):
# do user actions here
# this gets called repeatedly
return
例子
下面是一个完整的使用mechanize生成HTTP GET请求的用户脚本:
import mechanize
class Transaction(object): def run(self): br = mechanize.Browser()
br.set_handle_robots(False)
resp = br.open('http://www.example.com/')
resp.read()
下面的脚本增加了响应的断言:
import mechanize
class Transaction(object): def run(self): br = mechanize.Browser()
br.set_handle_robots(False)
resp = br.open('http://www.example.com/')
resp.read()
assert (resp.code == 200), 'Bad Response: HTTP %s' % resp.code assert ('Example Web Page' in resp.get_data())
下面的脚本使用了一个自定义的timer:
import mechanize
import time
class Transaction(object): def run(self):
br = mechanize.Browser()
br.set_handle_robots(False)
start_timer = time.time()
resp = br.open('http://www.example.com/') resp.read() latency = time.time() - start_timer
self.custom_timers['Example_Homepage'] = latency
高级的例子
通过表单填写,提交的方式进行Wikipedia搜索,例子中包含:自定义timer,断言,自定义请求头,思考时间。
import mechanize
import time
class Transaction(object):
def __init__(self):
pass
def run(self):
# create a Browser instance
br = mechanize.Browser()
# don't bother with robots.txt
br.set_handle_robots(False)
# add a custom header so wikipedia allows our requests
br.addheaders = [('User-agent', 'Mozilla/5.0 Compatible')]
# start the timer
start_timer = time.time()
# submit the request
resp = br.open('http://www.wikipedia.org/')
resp.read()
# stop the timer
latency = time.time() - start_timer
# store the custom timer
self.custom_timers['Load_Front_Page'] = latency
# verify responses are valid
assert (resp.code == 200), 'Bad Response: HTTP %s' % resp.code
assert ('Wikipedia, the free encyclopedia' in resp.get_data())
# think-time
time.sleep(2)
# select first (zero-based) form on page
br.select_form(nr=0)
# set form field
br.form['search'] = 'foo'
# start the timer
start_timer = time.time()
# submit the form
resp = br.submit()
resp.read()
# stop the timer
latency = time.time() - start_timer
# store the custom timer
self.custom_timers['Search'] = latency
# verify responses are valid
assert (resp.code == 200), 'Bad Response: HTTP %s' % resp.code
assert ('foobar' in resp.get_data()), 'Text Assertion Failed'
# think-time
time.sleep(2)
这个例子使用httplib生成HTTP GET请求,并且实现了详尽的时间:发送请求用的时间,接收响应用的时间,内容传输完成用的时间。
import httplib
import time
class Transaction(object):
def run(self):
conn = httplib.HTTPConnection('www.example.com')
start = time.time()
conn.request('GET', '/')
request_time = time.time()
resp = conn.getresponse()
response_time = time.time()
conn.close()
transfer_time = time.time()
self.custom_timers['request sent'] = request_time - start
self.custom_timers['response received'] = response_time - start
self.custom_timers['content transferred'] = transfer_time - start
assert (resp.status == 200), 'Bad Response: HTTP %s' % resp.status
if __name__ == '__main__':
trans = Transaction()
trans.run()
for timer in ('request sent', 'response received', 'content transferred'):
print '%s: %.5f secs' % (timer, trans.custom_timers[timer])
multi-mechanize使用matplotlib来生成报告。
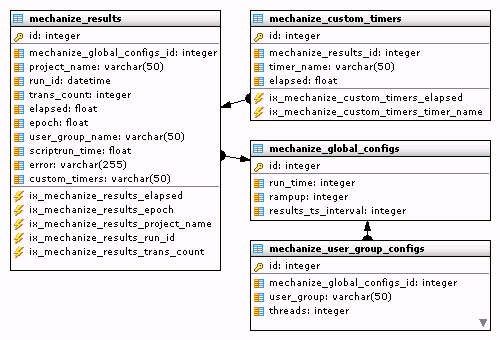
当测试运行完成后,测试数据和结果能够被存储到数据库。为了开启数据库支持,必须向配置文件config.cfg中增加results_database选项,results_database定义了数据连接串。
例子
results_database: sqlite:///results.db
依赖
数据库存储需要sqlalchemy
示例连接串
SQLite: sqlite:///dbname MySQL: mysql://user:password@localhost/dbname PostgreSQL: postgresql://user:password@host:port/dbname MS SQL Server: mssql://mydsn
结果数据库表