为什么要进行负载测试
随着 IT 基础架构的不断演进,API 逐渐承载大多数的数据交换。通过负载测试,可以在将 API 发布给用户之前,测试系统的吞吐量上限,以发现设计上的错误或验证系统的负载能力。
负载测试的主要目标是评估系统在不同负载下的性能和稳定性,确定系统的瓶颈和容量。具体目标包括:
- 测试系统的性能:负载测试可以测试系统在不同负载下的性能表现,包括响应时间、吞吐量、并发用户数等指标。
- 测试系统的稳定性:负载测试可以测试系统在高负载和极端情况下的稳定性,包括系统崩溃、错误和资源耗尽等情况。
- 确定系统的容量:负载测试可以确定系统可以处理的最大负载和容量,以便规划系统的容量和资源需求。
- 发现系统瓶颈:负载测试可以帮助发现系统的瓶颈,包括硬件资源、网络带宽、数据库性能等方面,以便进行优化和改进。
- 验证系统的可靠性:负载测试可以验证系统的可靠性和可用性,以确保系统可以满足用户的需求和期望。
通过负载测试,可以得到系统的性能和稳定性数据,帮助开发人员和系统管理员优化和改进系统,提高系统的可靠性和性能,提升用户体验。
Locust 是什么
Locust 是易于使用的、分布式的用户负载测试工具,可以用于 Web 站点或其它系统的负载测试,最后计算出系统能够处理多少并发用户。
Locust 的思想是:在测试期间,一大群"蝗虫"将攻击你的网站,每个"蝗虫"的行为都由你自己定义,同时可以在 Web 界面上实时地监控这群进程。这将帮助你更好地"进行战斗",在真正的用户进入之前,找出代码中的瓶颈。
Locust 是事件驱动的(使用 gevent),这使得它能够在单进程中处理数以千计的并发用户。虽然可能存在其它在给定的硬件上每秒能发起更多请求的工具,但是每个 Locust 用户的低开销,使它非常适合测试高并发的工作负载。
Locust 的特性
- 使用 Python 编写测试脚本
不需要笨重的 UI 或臃肿的 XML,只需像平时一样写代码。Locust 基于协程而非回调函数,允许像平时写阻塞 Python 代码一样写异步代码
- 分布式 & 可扩展 - 支持无数用户
Locust 支持在多台机器上分布式地运行负载测试,因为其基于事件驱动,所以一个 Locust 节点能够在单线程中处理数以千计的用户。模拟大量用户的一部分原因是:即使模拟许多用户,但是并非所有用户都同时访问系统,通常情况下用户是空闲的,思考接下来要做什么,所以每秒请求数 != 在线用户数
- 基于 Web 的 UI
Locust 提供整洁的 HTML + JS 用户接口,它实时地展示相关的测试细节。因为 UI 是基于 Web 的,所以它是跨平台的,并且很容易扩展
- 能够测试任何系统
虽然 Locust 面向 Web ,但它适用于任何系统的负载测试。只需要编写一个客户端,然后使用 Locust 运行,非常容易
- 易于 Hack
Locust 非常小,非常容易 Hack,IO 事件和协程这些重活都被委派给 gevent
安装
$ pip install locust或
$ easy_install locust安装 Locust 后,可以在 Shell 中使用 locust 命令。通过运行下面的命令查看可用的选项:
$ locust --help每个 HTTP 连接都打开一个新文件描述符。操作系统可能给每个用户所能打开的最大文件数量设置一个较低的限制,如果该限制少于测试中模拟的用户数,将发生失败。因此应该将操作系统默认的最大文件描述符数量增加到比模拟的用户数更大的值。具体如何做,依赖于使用的操作系统。
快速入门
下面是一个简单的例子:
from locust import HttpUser, TaskSet
def login(l): l.client.post("/login", {"username":"ellen_key", "password":"education"})
def index(l): l.client.get("/")
def profile(l): l.client.get("/profile")
class UserBehavior(TaskSet): tasks = {index: 2, profile: 1}
def on_start(self): login(self)
class WebsiteUser(HttpUser): tasks = [UserBehavior] min_wait = 5000 max_wait = 9000上述代码中定义多个 Locust 任务,Locust 任务是带有一个参数(TaskSet 实例)的 Python 可调用对象,这些任务被收集到 TaskSet 类的 tasks 属性中。HttpUser 类代表模拟的用户,在这个类中,我们定义模拟的用户在两次执行任务之间应该等待多久。TaskSet 类用于定义用户的行为,TaskSet 可以嵌套 TaskSet。
HttpUser 继承自 User,它添加了用于生成 HTTP 请求的属性 client - HttpSession 实例。
另一种更加便捷的声明任务的方式是使用 @task 装饰器,下面的代码与上面的代码等价:
from locust import HttpUser, TaskSet, task
class UserBehavior(TaskSet): def on_start(self): """ on_start is called when a Locust start before any task is scheduled """ self.login()
def login(self): self.client.post("/login", {"username":"ellen_key", "password":"education"})
(2) def index(self): self.client.get("/")
(1) def profile(self): self.client.get("/profile")
class WebsiteUser(HttpUser): tasks = [UserBehavior] min_wait = 5000 max_wait = 9000User 以及 HttpUser(HttpUser 是 User 的子类)支持为每个模拟用户指定在两次执行任务之间等待的最小和最大时间(min_wait 和 max_wait),以及其它用户行为。
启动 Locust:
如果上面的文件被命名为 locustfile.py,那么可以在同级目录下,使用如下命令来运行 Locust:
locust --host=http://example.com
如果 locust file 被放在其它地方,我们可以运行:
locust -f ../locust_files/my_locust_file.py --host=http://example.com
为通过多进程分布式地运行 Locust,我们应该在启动 master 进程时指定 --master 选项:
locust -f ../locust_files/my_locust_file.py --master --host=http://example.com
然后我们可以启动任意数量的 worker 进程:
xxxxxxxxxxlocust -f ../locust_files/my_locust_file.py --worker --host=http://example.com
如果我们想要在多台机器上分布式地运行 Locust,那么在启动 worker 时,必须指定 master 的host:
xxxxxxxxxxlocust -f ../locust_files/my_locust_file.py --worker --master-host=192.168.0.100 --host=http://example.com
打开 Locust 的 Web 接口
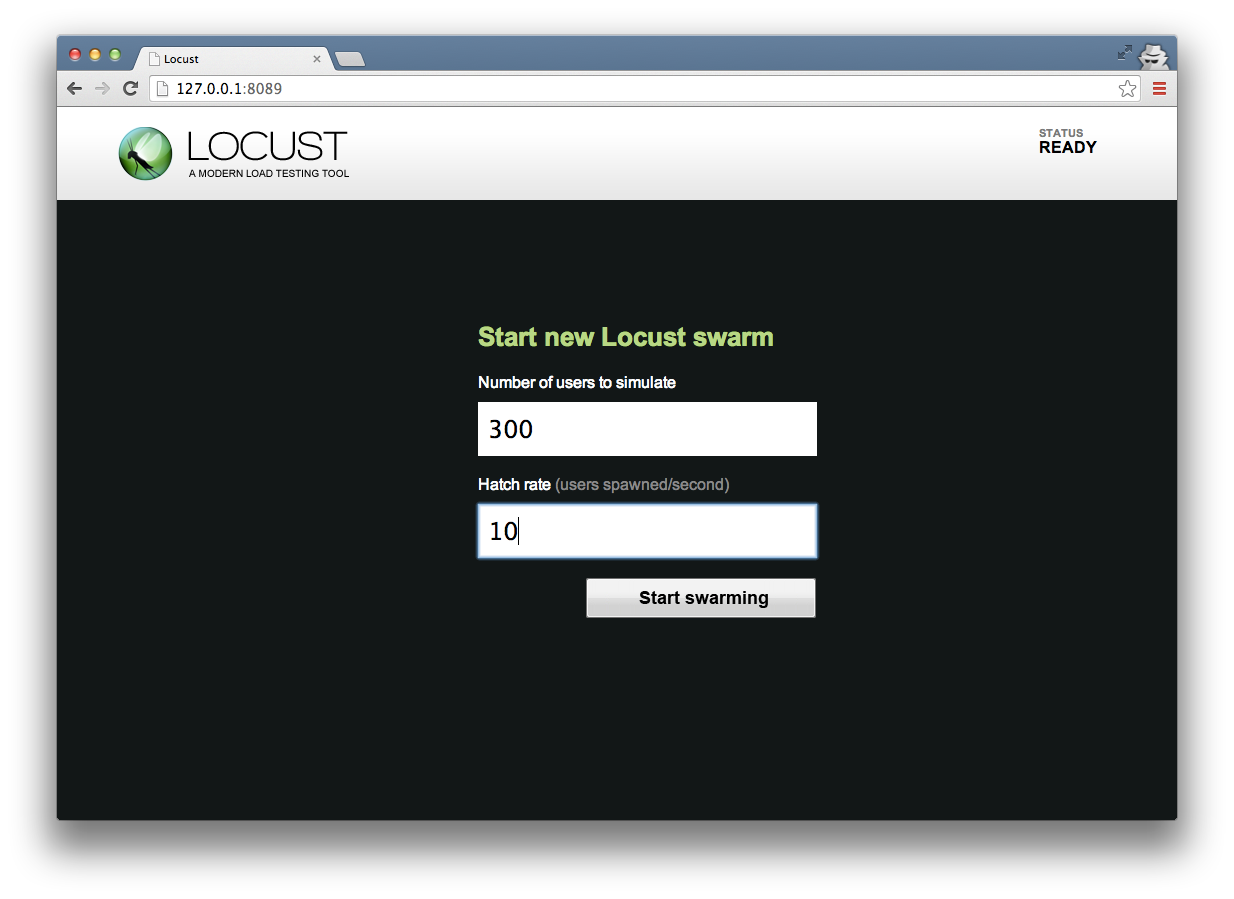
启动 Locust 后,可以打开浏览器,访问 http://127.0.0.1:8089,将看到 Locust 的欢迎页面:
编写 locustfile
locustfile 是普通 Python 文件,唯一的要求是它至少要声明一个类 --- 我们管它叫 user 类 --- 它继承自 User 类。
user 类:
每个 user 类代表一个用户,Locust 为每个模拟用户生成一个 user 类的实例,user 类应该定义以下属性:
tasks属性
tasks 属性用于定义用户的行为
min_wait和max_wait属性
除 tasks 属性外,还可以声明 min_wait 和 max_wait 属性,它们分别用于指定模拟用户在两次执行任务之间等待的最小和最大时间,单位是毫秒。min_wait 和 max_wait 的默认值是 1000,因此如果未声明 min_wait 和 max_wait,Locust 在执行每个任务之前总是等待 1 秒
当使用下面的 locustfile 时,用户在两次执行任务之间将等待 5 - 15 秒:
xxxxxxxxxxfrom locust import User, TaskSet, task
class MyTaskSet(TaskSet): def my_task(self): print("executing my_task")
class MyUser(User): tasks = [MyTaskSet] min_wait = 5000 max_wait = 15000也可以在 TaskSet 类中重写 min_wait 和 max_wait 。
weight属性
可以像这样从相同的文件中运行两个 user:
xxxxxxxxxxlocust -f locust_file.py WebUser MobileUser
如果希望使这些 user 中的某一个执行得更加频繁,可以在这些类上设置 weight 属性。对于下面的例子而言,Web 用户可能是 Mobile 用户的三倍:
xxxxxxxxxxclass WebUser(User): weight = 3 ....
class MobileUser(User): weight = 1 ....host属性
host 属性用于指定将要被加载的 URL 的前缀(比如 http://google.com)。通常在启动 Locust 时,通过 --host 选项指定它。如果 user 类中声明了 host 属性,并且命令行中未提供 --host 选项,那么将使用它
TaskSet 类:
TaskSet 类用于定义用户将要执行的任务集合。
当 TaskSet 开始执行时,它将从 tasks 属性中选择一个任务,执行它,然后等待 min_wait 到 max_wait 毫秒。之后它将调度另外一个任务来执行,等等。
TaskSet 可以嵌套,这意味着 TaskSet 的 tasks 属性可以包含另一个 TaskSet。当被嵌套的 TaskSet 被调度执行时,它将被实例化,并且从当前正在执行的 TaskSet 被调用。执行权将从当前正在执行的 TaskSet 转交到嵌套的 TaskSet,它将一直执行,直到抛出 InterruptTaskSet 异常,当调用 TaskSet.interrupt() 方法时,将抛出该异常。(第一个 TaskSet 将继续执行)
- 声明任务
为 TaskSet 声明任务的最典型的方式是使用 @task 装饰器。
下面是一个例子:
xxxxxxxxxxfrom locust import User, TaskSet, task
class MyTaskSet(TaskSet): def my_task(self): print("User instance (%r) executing my_task" % (self.user))
class MyUser(User): tasks = [MyTaskSet]@task 装饰器带一个可选的参数 weight,它用于指定任务的执行比例。在下面的例子中,task2 的执行次数是 task1 的两倍:
xxxxxxxxxxfrom locust import User, TaskSet, task
class MyTaskSet(TaskSet): min_wait = 5000 max_wait = 15000
(3) def task1(self): pass
(6) def task2(self): pass
class MyUser(User): tasks = [MyTaskSet]tasks属性
使用 @task 装饰器声明任务很方便,并且通常是最好的方式。但是也可以通过设置 tasks 属性来定义 TaskSet 的任务。
tasks 属性既可以是由 Python 可调用对象组成的列表,也可以是 <callable : int> 形式的字典,每个任务都是接受一个参数(正在执行这个任务的 TaskSet 实例)的 Python 可调用对象。下面是一个简单的例子:
xxxxxxxxxxfrom locust import User, TaskSet
def my_task(l): pass
class MyTaskSet(TaskSet): tasks = [my_task]
class MyUser(User): tasks = [MyTaskSet]如果 tasks 属性被指定为列表,那么将随机地从列表中选择将要被执行的任务;如果 tasks 是键为可调用对象,值为整型的字典,那么将使用整型作为比例,随机地选取将要被执行的任务。
因此在下面的 tasks 中:
xxxxxxxxxx{my_task: 3, another_task: 1}my_stask 被执行的次数是 another_task 的三倍
TaskSet支持嵌套
真正的网站通常由多个子区域以分层的方式组合而成。嵌套的 TaskSet 支持把模拟用户的行为定义得更加逼真,比如我们可以定义拥有如下结构的 TaskSet:
xxxxxxxxxxMain user behaviourIndex pageForum pageRead threadReplyNew threadView next pageBrowse categoriesWatch movieFilter moviesAbout page
与指定任务时一样,通过使用 tasks 属性,定义嵌套的 TaskSet。只不过 tasks 中的元素不指向 Python 可调用对象,而是指向另一个 TaskSet。
xxxxxxxxxxclass ForumPage(TaskSet): (20) def read_thread(self): pass
(1) def new_thread(self): pass
(5) def stop(self): self.interrupt()
class UserBehaviour(TaskSet): tasks = {ForumPage: 10}
def index(self): pass在上面的例子中,当 UserBehaviour 执行时,ForumPage 将被选择执行,也就是 ForumPage 将开始执行。ForumPage 将从它自己的任务中选择一个,并且执行它,然后等待,等等。
在上面的例子中,有个地方值得注意,那就是 ForumPage 的 stop() 方法里调用了 self.interrupt()。它的作用是中断 ForumPage,将执行控制权交回给 UserBehaviour。如果在 ForumPage 中没有调用 interrupt(),那么一旦 ForumPage 启动,Locust 将不停地执行 ForumPage。
可以通过对内部类使用 @task 装饰器来声明嵌套的 TaskSet,就像我们声明普通任务一样:
xxxxxxxxxxclass MyTaskSet(TaskSet): class SubTaskSet(TaskSet): def my_task(self): passon_start()方法
可以给 TaskSet 类定义 on_start() 方法,当模拟用户开始执行 TaskSet 时,on_start() 方法将被调用。
- 引用 User 实例或父 TaskSet 实例
TaskSet 实例的 user 属性指向它的 User 实例,parent 属性指向它的父 TaskSet。
生成 HTTP 请求:
到现在为止,本文已经讲述任务调度部分,为真正地给系统进行负载测试,我们需要生成 HTTP 请求,HttpUser 类可以解决这个问题。当使用 HttpUser 类时,每个实例都有一个属性 client --- 它是能够用于生成 HTTP 请求的 HttpSession 实例。
xxxxxxxxxxclass HttpUser: 代表被“孵化”出来的、用于“攻击”要进行负载测试的系统的 HTTP 用户。 用户行为由 tasks 属性来定义。 这个类在初始化时,将创建 client 属性,client 属性是支持在请求之间保持用户会话的 HTTP 客户端。
client = None当从 HttpUser 类继承时,我们可以使用它的 client 属性生成 HTTP 请求,下面是一个例子:
xxxxxxxxxxfrom locust import HttpUser, TaskSet, task
class MyTaskSet(TaskSet): (2) def index(self): self.client.get("/")
(1) def about(self): self.client.get("/about/")
class MyUser(HttpUser): tasks = [MyTaskSet] min_wait = 5000 max_wait = 15000使用上面的 user 类,每个模拟用户在请求之间都将等待 5 - 15 秒,并且 / 的请求次数是 /about/ 的两倍。
用心的读者可能会觉得很奇怪:在 TaskSet 内部我们使用 self.client 而非 self.user.client 引用 HttpSession 实例,我们能这么做是因为 TaskSet 类有一个便捷的、被称作 client 的属性,它简单地返回 self.user.client。
使用 HTTP 客户端:
每个 HttpUser 实例都有一个指向 HttpSession 实例的 client 属性。HttpSession 类其实是 requests.Session 的子类,能够使用 get、post、put、delete、head、patch 和 options 方法生成 HTTP 请求,并且响应被报告到 Locust 的统计中。HttpSession 实例在请求之间保持 Cookie,以便它能登陆网站,在请求之间保持会话。也可以从 User 实例的 TaskSet 实例直接引用 client 属性,以便在任务内部,能够很容易地取出 client,生成 HTTP 请求。
下面是一个简单的例子,用于生成到 /about 的 GET 请求(在这个例子中,我们假定 self 是 TaskSet 或 HttpLocust 实例):
xxxxxxxxxxresponse = self.client.get("/about")print("Response status code:", response.status_code)print("Response content:", response.content)下面是一个生成 POST 请求的例子:
xxxxxxxxxxresponse = self.client.post("/login", {"username": "testuser", "password": "secret"})- 安全模式
HTTP 客户端被配置成以安全模式运行,任何由于连接错误、超时之类的原因而失败的请求都不抛出异常,而是返回空的、虚拟的 Response 对象,在 Locust 的统计中该请求被报告为失败。虚拟的 Response 对象的 content 属性被设置为 None,status_code 属性被设置为 0。
- 手动控制请求被视为成功还是失败
默认情况下,除非 HTTP 响应码是 OK(2XX),否则请求将被标记为失败。在大多数情况下,默认情况就是我们想要的。然而有时 --- 比如期望返回 404,或者测试一个即使发生错误,仍然返回 200 OK 的系统,就存在手动控制 Locust 将请求视为成功还是失败的需求。
通过使用 catch_response 参数和 with 语句,可以把一个响应码是 okay 的请求标记成失败:
xxxxxxxxxxwith client.get("/", catch_response=True) as response: if response.content != "Success": response.failure("Got wrong response")正如可以把响应码为 OK 的请求标记为失败,也可以使用 catch_response 参数和 with 语句将返回错误状态码的请求在统计中报告为成功:
xxxxxxxxxxwith client.get("/does_not_exist/", catch_response=True) as response: if response.status_code == 404: response.success()- 将到具有动态参数的 URL 的请求进行分组
对于大多数网站来说,拥有 URL 中包含某种动态参数的页面非常普遍。通常在 Locust 的统计中,将这些 URL 分成一组非常有意义。可以通过给 HttpSession 实例的请求方法传递 name 参数的方式,来完成这件事。比如:
xxxxxxxxxx# Statistics for these requests will be grouped under: /blog/?id=[id]for i in range(10): client.get("/blog?id=%i" % i, name="/blog?id=[id]")分布式地运行 Locust
一旦单机无法满足需要模拟的用户数量,Locust 支持通过多机分布式地运行负载测试。
为分布式地运行 Locust,需要使用 --master 标记,以 Master 模式启动 Locust 实例,Master 节点上将运行 Locust 的 Web 接口,通过 Web 接口可以开始测试以及查看统计。Master 节点本身不模拟任何用户。必须使用 --worker 和 --master-host(用于指定 Master 节点的 IP 或主机名)标记启动一个或多个 Worker 节点。
比较通用的设置是:在一台机器上运行单独的 Master,在 Worker 机器的每个核心上运行一个 Worker 实例。
当分布式地运行 Locust 时,Master 节点和每个 Worker 节点上都必须有 Locust 测试脚本的拷贝。
例子:
以 Master 模式启动 Locust:
xxxxxxxxxxlocust -f my_locustfile.py --master然后在每台 Worker 上(用 Master 机器的 IP 替换 192.168.0.14):
xxxxxxxxxxlocust -f my_locustfile.py --worker --master-host=192.168.0.14选项:
--master
以 Master 模式运行 Locust,Web 接口运行在该节点上
--worker
以 Worker 模式运 Locust
--master-host=X.X.X.X
和 --worker 一起使用,用于设置 Master 节点的 IP 或主机名(默认是 127.0.0.1)
--master-port=5557
和 --worker 一起使用,用于设置 Master 节点的端口号(默认是 5557),Locust 既使用指定的端口号,又使用指定的端口号 + 1,因此如果将该选项设置为 5557,那么 Locust 既使用 5557,也使用 5558
--master-bind-host=X.X.X.X
和 --master 一起使用,决定 master 节点绑定到哪个网络接口,默认是 "*"(所有可用的网络接口)
--master-bind-port=5557
和 --master 一起使用,决定 master 节点监听哪个网络端口(默认是5557)。Locust 既使用指定的端口号,又使用指定的端口号 + 1,因此如果将该选项设置为 5557,那么 Locust 既使用 5557,也使用 5558
测试非 HTTP 系统
Locust 仅对 HTTP/HTTPS 提供内建支持。但是可以通过编写触发 request 的自定义客户端的方式,将它扩展到支持所有系统的负载测试。
示例:编写 XML-RPC User/Client
假定我们有一个想要进行负载测试的 XML-RPC 服务:
import randomimport timefrom xmlrpc.server import SimpleXMLRPCServer
def get_time(): time.sleep(random.random()) return time.time()
def get_random_number(low, high): time.sleep(random.random()) return random.randint(low, high)
server = SimpleXMLRPCServer(("localhost", 8877))print("Listening on port 8877...")server.register_function(get_time, "get_time")server.register_function(get_random_number, "get_random_number")server.serve_forever()可以通过包装 xmlrpc.client.ServerProxy 构建通用的 XML-RPC 客户端:
import timefrom xmlrpc.client import ServerProxy, Fault
from locust import User, task
class XmlRpcClient(ServerProxy): """ XmlRpcClient is a wrapper around the standard library's ServerProxy. It proxies any function calls and fires the *request* event when they finish, so that the calls get recorded in Locust. """
def __init__(self, host, request_event): super().__init__(host) self._request_event = request_event
def __getattr__(self, name): func = ServerProxy.__getattr__(self, name)
def wrapper(*args, **kwargs): request_meta = { "request_type": "xmlrpc", "name": name, "start_time": time.time(), "response_length": 0, # calculating this for an xmlrpc.client response would be too hard "response": None, "context": {}, # see HttpUser if you actually want to implement contexts "exception": None, } start_perf_counter = time.perf_counter() try: request_meta["response"] = func(*args, **kwargs) except Fault as e: request_meta["exception"] = e request_meta["response_time"] = (time.perf_counter() - start_perf_counter) * 1000 self._request_event.fire(**request_meta) # This is what makes the request actually get logged in Locust return request_meta["response"]
return wrapper
class XmlRpcUser(User): """ A minimal Locust user class that provides an XmlRpcClient to its subclasses """
abstract = True # dont instantiate this as an actual user when running Locust
def __init__(self, environment): super().__init__(environment) self.client = XmlRpcClient(self.host, request_event=environment.events.request)
# The real user class that will be instantiated and run by Locust# This is the only thing that is actually specific to the service that we are testing.class MyUser(XmlRpcUser): host = "http://127.0.0.1:8877/"
def get_time(self): self.client.get_time()
def get_random_number(self): self.client.get_random_number(0, 100)事件钩子
Locust 有许多事件钩子,可以使用它们以不同方式扩展 Locust。
下面的例子展示如何设置在每个请求完成后触发的事件监听器:
from locust import events
.request.add_listenerdef my_request_handler(request_type, name, response_time, response_length, response, context, exception, start_time, url, **kwargs): if exception: print(f"Request to {name} failed with exception {exception}") else: print(f"Successfully made a request to: {name}") print(f"The response was {response.text}")查看 Event Hooks 获取全部可用的事件列表。
增加 Web 路由
Locust 使用 Flask 提供 Web UI,因此向 Web UI 中增加 Web 端点非常容易。通过监听 init 事件的方式,可以获得 Flask App 实例的引用,并且可以使用它设置新路由:
from locust import events
.init.add_listenerdef on_locust_init(environment, **kw): .web_ui.app.route("/added_page") def my_added_page(): return "Another page"