什么是任务队列?
任务队列是一种在进程或机器之间分发任务的机制。
任务队列的输入是被称为任务(task)的工作单元。专用的工作进程会时刻监控任务队列,来获取要执行的任务。
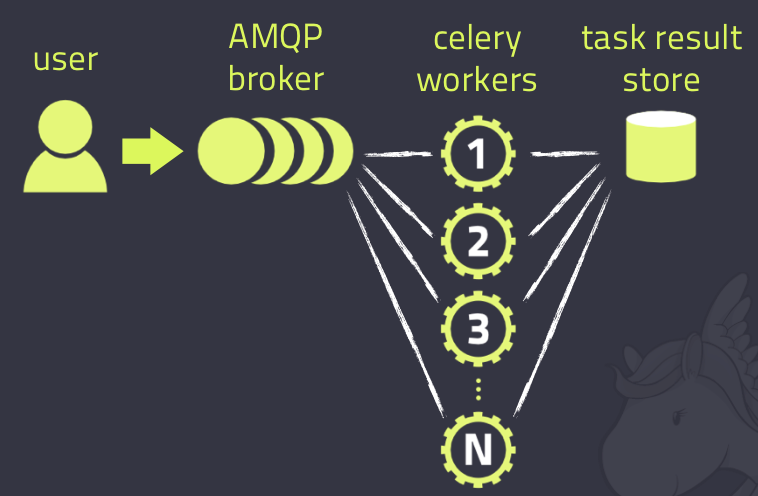
celery的client和worker通过消息来“沟通”,但是celery本身并不提供消息服务,因此它使用第三方的消息服务来传递任务,目前celery支持的消息服务有RabbitMQ、Redis甚至是数据库。为了开始一个任务,client需要向队列中发送任务消息,然后broker会把任务投递给worker处理。
一个celery系统可以包含多个worker和broker,以便实现高可用和可水平扩展。
celery是用python编写的,但是协议可以用任何语言来实现,目前为止有用于ruby的RCelery,用于nodejs的node-celery,和一个php客户端。其他的语言也可以通过webhooks来调用celery的task。
celery的架构如下
Celery需要什么?
celery需要一个消息传输系统来发送和接受消息。RabbitMQ和Redis支持celery的全部特性。但是celery也支持许多其他的试验性的解决方案,包括使用SQLite用于本地开发。
celery可以既部署在单机,也可以部署在多机上,甚至可以跨IDC部署。
安装
可以使用pip或easy_install来安装celery:
sudo pip install -U celery
或
sudo easy_install -U celery
也可以去官网下载源代码,安装。
五分钟上手
下面的教程是celery的最基本的使用方式,包括:
- 选择和安装一个消息服务器
- 创建一个任务
- 启动worker,以及调用任务
- 追踪任务的状态,以及获取任务的返回结果
celery支持的消息服务器,可以点击这里进行查看,在本教程中,选用了Redis。
使用celery所需要的第一个东西就是Celery类的实例,它被称为celery应用程序或简称为app。这个Celery类的实例是celery所能做的所有的事情的一个入口点,比如:创建任务、管理worker等,因此其他模块也必须能够导入它。
在本教程中,所有的代码都包含在一个单独的模块中,但是对与大型项目而言,通常会给celery app创建一个专用模块。
下面创建一个文件tasks.py:
from celery import Celery
app = Celery("tasks",
broker="redis://redis:hybrid_test_cases@100.69.206.175:6379/3",
backend="redis://redis:hybrid_test_cases@100.69.206.175:6379/4",
)
@app.task
def add(x, y):
return x + y
if __name__ == "__main__":
app.worker_main()
Celery类的构造函数的第一个参数是当前模块的名称,在自动生成任务名称的时候会用到它;broker关键字参数指定了要使用的消息服务器的URL,这里使用的Redis。
在这个例子中,只定义了一个任务:add,它返回两个数字的和。
接下来要做的是,运行celery worker,可以通过使用worker子命令执行celery,来启动一个celery worker:
celery worker -A tasks:app --loglevel=debug
在生产环境中,需要在后台以守护进程的方式运行celery worker,想要完成这个任务,可以使用一些进程管理工具,比如supervisord等。
为了查看全部可用的命令行选项,可以执行下面的命令:
celery worker --help或
celery help
在启动了worker之后,接下来学习如何调用task。为了调用task,需要使用task的delay方法。
delay方法其实是apply_async方法的一种简写方式,使用apply_async方法不仅可以给task传递参数,还可以传递执行选项(后面会介绍)。
$python
Python 2.7.6 (default, Oct 22 2015, 14:13:28)
[GCC 4.4.6 20110731 (Red Hat 4.4.6-3)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> from tasks import add
>>> async_result = add.delay(3, 4)
>>> async_result.get()
7
这个任务已经被之前启动的worker处理了,可以通过worker控制台的输出来验证。
调用任务会返回一个AsyncResult实例,它能够用于检查任务的状态,比如等待任务完成,获取任务的返回值(如果任务失败,还可以获取异常和traceback信息)。但是这些默认是不开启的。除非通过backend参数给Celery配置一个result backend(后续也会介绍)。
如果想要追踪任务的状态,celery需要一个存储和发送状态的地方。有多种内建的result backend可供选择:
SQLAlchemy ORM,Memcached,Redis,AMQP,MongoDB。或者是自己定义result backend。
比如可以使用rpc作为result backend,celery会把状态作为消息发送给result backend。result backend可以通过Celery类的构造函数的backend参数来指定,如果使用配置模块的话,也可以通过task_result_backend来指定:
app = Celery('tasks', backend='rpc://', broker='amqp://')
再比如,可以使用Redis作为result backend,使用RabbitMQ作为消息服务器(Redis + RabbitMQ是一个非常流行的组合):
app = Celery('tasks', backend='redis://localhost', broker='amqp://')
更多关于result backend的细节,请查看这个链接。
在配置了result backend之后,调用task,就可以使用调用task返回的AsyncResult实例了:
>>> result = add.delay(4, 4)
ready()方法用于检查任务是否完成:
>>> result.ready()
True
也可以等待任务的完成:
>>> result.get(timeout=0.1)
8
如果任务抛出了异常,get()会重新抛出异常,但是可以通过指定propagate参数,来重写这个默认行为:
>>> result.get(propagate=False)
如果任务抛出异常,那么也可以获取原始的traceback信息:
>>> result.traceback
查看celery.result,获取完整的result对象引用。
在大多数使用情形下,默认的配置是不够的。因此为了使celery能按照预期的方式进行工作,那么需要调整一些配置。关于celery的配置选项,可查看Configuration and defaults。
既可以直接在celery应用程序上直接设置配置选项,也可以使用专用的配置模块。比如,可以将task_serializer配置为json:
app.conf.task_serializer = 'json'
在客户端和worker之间传输的数据的数据需要被序列化,因此celery中的每个消息都有一个用于描述编码该消息所使用的序列化方法的content_type头。
默认的序列化方式是pickle,可以通过设置task_serializer,改变每个单独的任务,甚至每条消息的序列化方式。celery内建支持pickle、json、YAML和msgpack,也支持增加自定义的序列化方式(需要注册到Kombu serializer registry)。
如果一次配置多个setting,可以使用update方法:
app.conf.update(
task_serializer='json',
accept_content=['json'], # Ignore other content
result_serializer='json',
timezone='Europe/Oslo',
enable_utc=True,
)
对于大型项目而言,使用专用的配置模块是非常有用的,事实上,硬编码周期性任务的时间间隔和任务路由选项是不推荐的,因为比较好的方式是在一个“地方”集中的管理这些配置。
可以通过调用app.config_from_object()方法,给Celery实例指定配置模块:
app.config_from_object('celeryconfig')
在这个例子中,配置模块叫celeryconfig,但是可以使用任何模块名称。
在当前目录或python模块搜索路径中,必须有一个叫celeryconfig.py的模块。它可能如下一样:
#celeryconfig.py
broker_url = 'amqp://'
result_backend = 'rpc://'
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
timezone = 'Europe/Oslo'
enable_utc = True
为了验证配置文件能正确的工作,不包含任何语法错误,可以尝试导入它:
$python -m celeryconfig
可以查看 Configuration and defaults,获取完整的配置选项。
下面来说明一下,使用配置文件的好处。比如,可以把一个不重要的任务路由到一个专用的队列:
#celeryconfig.py
task_routes = {
'tasks.add': 'low-priority',
}
或者是给这种任务限速,以便每分钟,只处理十个这种类型的任务(10/m):
#celeryconfig.py
task_annotations = {
'tasks.add': {'rate_limit': '10/m'}
}
如果使用RabbitMQ或Redis作为消息服务器的话,也可以在运行时给任务设置一个新的速率限制:
$ celery -A tasks control rate_limit tasks.add 10/m
worker@example.com: OK
new rate limit set successfully
查看Routing Tasks,来阅读更多关于任务路由的细节,查看task_annotations,来阅读更多关于annotation的细节,查看Monitoring and Management Guide,来阅读更多关于远程控制命令和如何监控worker的细节。
所有的任务,默认都处于PENDDING状态,因此PENDDING其实相当于unkown。当任务被发送的时候,celery不会更新它的状态,任何没有状态更新历史的任务都被假定是PENDDING的(对于一个不存在的任务,它的状态也是PENDDING的)。
当一个任务,长期处于PENDDING状态,那么应该:
- 确保任务没有开启
ignore_result选项,因为当开启了这个选项的时候,worker不会更新任务的状态
- 确保没有启用
task_ignore_result设置
- 确保没有任何“老的”worker仍然在运行
很容易“误开启”多个worker,因此在启动一个新的worker之前,要确保之前的worker被正确的关闭;否则,没有配置期望的result backend的“老的”worker会劫持任务。
在启动worker时,--pidfile参数的值应该被设置成绝对路径,以确保:“老的”worker仍然在运行的时候,无法启动新的worker。
应用程序
celery类库在使用之前必须先实例化,这个实例被称为“应用程序”(或者简称app)。
“应用程序”是线程安全的,以便多个具有不同配置,组件和任务的“应用程序”可以在同一个进程空间中共同存在。
下面创建一个“应用程序”:
>>> from celery import Celery
>>> app = Celery()
>>> app
最后一行展示了“应用程序”的文本表现形式,它包含celery类的名称(Celery),当前主模块名称(__main__)和这个对象的内存地址(0x7fb5d55a3fd0)。
主模块名称
这三个信息中只有一个是重要的,那就是主模块名称。
在celery中,当发送一个任务消息的时候,这个消息并不会包含任何源代码,只会包含要执行的任务名称。这种工作方式与因特网上主机名的工作方式相似:每个worker都会维护一个任务名称到它们真正的函数的映射,这个映射被成为task registy。
定义任务的时候,它也将被添加到本地任务记录:
>>> from celery import Celery
>>> app = Celery()
>>> app
>>> @app.task
... def add(x, y):
... return x + y
...
>>> add
<@task: __main__.add of __main__:0x7fb5d55a3fd0>
>>> add.name
'__main__.add'
>>> app.tasks["__main__.add"]
<@task: __main__.add of __main__:0x7fb5d55a3fd0>
又一次看到了__main__。这是因为celery不能检测任务函数属于哪一个模块,当没有给任务指定名称的时候,它使用主模块名称作为任务名称的前缀。
但是这只在有限的使用情形下会出问题:
1,定义任务的模块被作为一个程序运行。
2,“应用程序”是在Python shell (REPL)中创建的。
任务模块也可以使用app.worker_main()来启动一个worker:
tasks.py:
from celery import Celery
app = Celery()
@app.task
def add(x, y): return x + y
if __name__ == '__main__':
app.worker_main()
当这个模块执行的时候,任务会被自动命名为__main__.xxxx,但是当这个模块被其它进程导入的时候,也就是调用任务的时候,任务会被命名为tasks.xxxx(模块的真正名称):
>>> from tasks import add
>>> add.name
tasks.add
也可以为主模块指定另外一个名称:
>>> app = Celery('tasks')
>>> app.main
'tasks'
>>> @app.task
... def add(x, y):
... return x + y
>>> add.name
tasks.add
配置
可以设置许多选项来改变celery的行为,同时可以直接在app实例上设置这些选项,也可以使用专用的配置模块。
可以通过app.conf来获取配置:
>>> app.conf.CELERY_TIMEZONE
'Europe/London'
也可以通过app.conf直接设置配置值:
>>> app.conf.CELERY_ENABLE_UTC = True
或者通过update方法一次更新多个key:
>>> app.conf.update(
... CELERY_ENABLE_UTC=True,
... CELERY_TIMEZONE='Europe/London',
...)
配置对象包含多个字典,celery按照下面的顺序从这些字典中获取配置值:
1,运行时作出的改变(调用task时指定的执行选项)
2,配置模块(如果有的话)
3,默认配置(celery.app.defaults)
通过app的add_defaults方法可以添加新的默认值。
config_from_object
app.config_from_object()从一个配置对象加载配置。
这个配置对象既可以是配置模块,也可以是任何具有配置属性的对象。
注意:当调用config_from_object()的时候,任何先前设置的属性都会重置,所以如果想要添加额外的配置,都应该在config_from_object()之后执行。
例1:使用模块名称
from celery import Celery
app = Celery()
app.config_from_object('celeryconfig')
celeryconfig模块的示例如下:
# celeryconfig.py
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Europe/London'
例2:使用配置模块
贴士:
推荐使用模块的名称,因为这意味着当使用prefork池的时候,模块不必被序列化。如果遇到了配置文件pickle错误的时候,那么请尝试使用模块的名称。
from celery import Celery
app = Celery()
import celeryconfig
app.config_from_object(celeryconfig)
例3:使用配置类/对象
from celery import Celery
app = Celery()
class Config:
CELERY_ENABLE_UTC = True
CELERY_TIMEZONE = 'Europe/London'
app.config_from_object(Config)
# or using the fully qualified name of the object:
# app.config_from_object('module:Config')
config_from_envvar
app.config_from_envvar()从一个环境变量获取配置模块名称。
比如-从一个叫CELERY_CONFIG_MODULE的环境变量所制定的模块加载配置:
import os
from celery import Celery
#: Set default configuration module name
os.environ.setdefault('CELERY_CONFIG_MODULE', 'celeryconfig')
app = Celery()
app.config_from_envvar('CELERY_CONFIG_MODULE')
可以通过环境变量来指定要使用的配置模块:
$ CELERY_CONFIG_MODULE="celeryconfig.prod" celery worker -l info
删除配置
当想要打印出配置作为调试信息的时候,也可能想要过滤掉密码,apikey等敏感信息。celery提供了一些用于展现配置的工具,其中一个是humanize:
>>> app.conf.humanize(with_defaults=False, censored=True)
这个函数返回一个平板状的字符串。默认情况下,(返回的字符串中)只会包含改变的配置,但是也可以通过改变with_defaults参数,来包含默认的键和值。
如果想要把配置转换为字典,那么应该使用table()方法:
>>> app.conf.table(with_defaults=False, censored=True)
请注意:celery并不能移除所有的敏感信息,因为它只是使用一个正则表达式去搜索键。如果添加了包含敏感信息的自定义配置,那么应该把键命名为celery认为是密码的名称。
当名字包含这些子串中的任意一个的时候,那么这个配置项(在展示的时候,)就会被删除:
API, TOKEN, KEY, SECRET, PASS, SIGNATURE, DATABASE。
lazy策略
“应用程序”实例采用了lazy策略,这意味着直到真正需要的时候,它才会被计算。
创建一个Celery实例,只会做下面的事情:
1,创建一个用于事件的逻辑时钟实例。
2,创建任务记录。
3,把它自己设置为current app(如果关闭了set_as_current参数,则不会设置自己为current app)。
4,调用app.on_init()回调函数(默认这个回调函数什么也不做)。
当app.task()装饰器被调用的时候,它不会真正的创建任务,而是延迟任务的创建直到任务被使用,或者是在“应用程序”finalized之后。
下面的例子展示了,直到使用任务或访问任务的属性之后(在这个例子中是repr()),任务才被创建:
>>> @app.task
>>> def add(x, y):
... return x + y
>>> type(add)
>>> add.__evaluated__()
False
>>> add # <-- causes repr(add) to happen
<@task: __main__.add>
>>> add.__evaluated__()
True
“应用程序”的finalization发生在显式地调用app.finalize()方法,或者是隐式地访问app.tasks的属性之后。
“应用程序”在finalized之后,会:
1,拷贝必须在“应用程序”之间共享的任务:
任务默认是共享的。但是如果把task装饰器的shared参数设置为False,那么这个任务就是它所绑定到的“应用程序”私有的。
2,计算所有挂起的task装饰器
3,确保所有的任务都被绑定到current_app:
任务被绑定到“应用程序”,以便它们能从配置读取默认值。
“default app”
过去,celery只有一个基于模块的API,为了向后兼容,老的API仍然存在。
celery总是会创建一个特殊的app,那就是“default app”,在没有实例化自定义的app的时候,它会被使用。
celery.task模块的存在就是为了容纳老的API,当使用自定义的app的时候,不应该使用这个模块。应该总是使用app实例上的方法,而不是这个基于模块的API。
比如说,老的Task基类启用了许多兼容的特性,然而这些特性可能并不兼容更新的特性,比如task方法。
from celery.task import Task # << OLD Task base class.
from celery import Task # << NEW base class.
推荐使用新的基类,即使正在使用老的基于模块的api。
破坏app链
虽然可以依赖被设置的current app,但是最好总是把app实例传递给任何需要它的地方。
我们称之为“app链”,因为它创建了一个依赖于被传递的app的实例的链。
下面是一个糟糕的例子:
from celery import current_app
class Scheduler(object):
def run(self):
app = current_app
比较好的做法是,Scheduler应该带app作为参数:
class Scheduler(object):
def __init__(self, app):
self.app = app
实际上celery使用celery.app.app_or_default(),以便所有的代码都能使用基于模块的兼容的API。
from celery.app import app_or_default
class Scheduler(object):
def __init__(self, app=None):
self.app = app_or_default(app)
在开发模式下,可以通过设置CELERY_TRACE_APP环境变量,在app链打破的时候,抛出异常:
$ CELERY_TRACE_APP=1 celery worker -l info
API的发展:
在过去的三年中,celery的api作出了很多改变。
比如说,开始的时候,可以使用任何可调用对象作为一个任务:
def hello(to):
return 'hello {0}'.format(to)
>>> from celery.execute import apply_async
>>> apply_async(hello, ('world!', ))
或者也可以创建一个Task类,来设置特定的选项或重写其他的行为:
from celery.task import Task
from celery.registry import tasks
class Hello(Task):
send_error_emails = True
def run(self, to):
return 'hello {0}'.format(to)
tasks.register(Hello)
>>> Hello.delay('world!')
后来,认为随意地传递可调用对象是anti模式,因为它使得使用序列化非常困难,因此这个特性在2.0中移除了,使用task装饰器来代替它:
from celery.task import task
@task(send_error_emails=True)
def hello(x):
return 'hello {0}'.format(to)
抽象的Task类
使用task()装饰器创建的所有的任务都继承自“应用程序”的Task基类。
可以使用base参数指定一个不同的基类:
@app.task(base=OtherTask):
def add(x, y):
return x + y
自定义的task类应该继承自中立的基类:celery.Task
from celery import Task
class DebugTask(Task):
abstract = True
def __call__(self, *args, **kwargs):
print('TASK STARTING: {0.name}[{0.request.id}]'.format(self))
return super(DebugTask, self).__call__(*args, **kwargs)
提示:
在重写task的__call__方法的时候,调用父类的__call__方法是非常重要的,以便在任务被直接调用的时候,基类的call方法能够设置被使用的默认的请求。
中立的基类非常重要,因为它没有绑定到任何特定的app。这个类的具体的子类会被绑定(到特定的app)。因此应该把这个通过的基类标记为abstract。
一旦任务被绑定到了app,它就可以读取配置,设置默认值等等。
可以通过改变“应用程序”的Task属性,来改变它的默认的基类:
>>> from celery import Celery, Task
>>> app = Celery()
>>> class MyBaseTask(Task):
... abstract = True
... send_error_emails = True
>>> app.Task = MyBaseTask
>>> app.Task
>>> @app.task
... def add(x, y):
... return x + y
>>> add
<@task: __main__.add>
>>> add.__class__.mro()
[>,
,
,
]
任务
任务是celery“应用程序”的积木。
任务是能够在任何可调用对象外部创建的类。它扮演着双重角色:一方面,它定义了在任务被调用的时候要做的事情(发送任务消息);另一方面,它也定义了在worker收到任务消息的时候要做的事情。
每个任务都有一个唯一的名称,这个名称在任务消息中被引用,以便worker能够找到要执行的函数。
直到任务消息被一个worker告知已收到,它都不会消失。worker可以预取许多消息,假设worker被杀死了,那么这些消息会被重新投递到其他的worker。
理想情况下,任务函数应该是幂等的,也就是说:使用相同的参数多次调用函数,不会导致预料之外的影响。因为worker无法检测任务是否是幂等的,所以默认行为是:在任务执行之前,worker就告知队列已经收到了消息,以便一个已经开始的任务绝不会被重复执行。
如果任务是幂等的,可以设置acks_late选项,来让worker在任务返回之后再告知队列已经收到消息。可以进入Should I use retry or acks_late页面查看FAQ。
基础
可以使用task()装饰器,从任何可调用对象的外部创建任务:
from .models import User
@app.task
def create_user(username, password):
User.objects.create(username=username, password=password)
也有许多任务选项可以设置,它们可以被指定为装饰器的参数。
@app.task(serializer='json')
def create_user(username, password):
User.objects.create(username=username, password=password)
多个装饰器
当和task()装饰器一起使用多个装饰器的时候,必须保证task装饰器最后被应用(在python中,意味着task装饰器必须是列表中的第一个)。
@app.task
@decorator2
@decorator1
def add(x, y):
return x + y
如何导入task装饰器?app是什么??
可以通过celery“应用程序”实例来使用task()装饰器。
如果正在使用django或仍然在使用老的基于模块的API,那么可以象下面这样来导入task()装饰器:
from celery import task
@task
def add(x, y):
return x + y
任务名称
每个任务都有一个唯一的名称。如果没有提供自定义的名称,那么会自动生成一个任务名称(主模块名.函数名)。
>>> @app.task(name='sum-of-two-numbers')
>>> def add(x, y):
... return x + y
>>> add.name
'sum-of-two-numbers'
最好的方式是使用模块名作为一个名称空间,通过这种方式,如果在其他模块中定义了一个同名任务,不会产生名称冲突。
>>> @app.task(name='tasks.add')
>>> def add(x, y):
... return x + y
可以通过访问task的name属性,来获取task的名称:
>>> add.name
'tasks.add'
如果模块名称是tasks.py,那么自动生成的名称是:
tasks.py:
@app.task
def add(x, y):
return x + y
>>> from tasks import add
>>> add.name
'tasks.add'
自动命名和相对导入
相对导入和自动命名一起使用会产生问题,因此如果使用了相对导入的话,那么需要显式的设置任务名称。
下面是一个会导致任务被命名为不同名称的例子:
>>> from project.myapp.tasks import mytask
>>> mytask.name
'project.myapp.tasks.mytask'
>>> from myapp.tasks import mytask
>>> mytask.name
'myapp.tasks.mytask'
这是因为worker和client在不同的名称下导入了模块。
因为必须考虑以何种方式导入模块,才是最好的。
通常,不应该使用老式的相对导入:
from module import foo # BAD!
from proj.module import foo # GOOD!
也推荐使用新式的相对导入:
from .module import foo # GOOD!
如果想要使用一个已经大量使用这种导入模式的celery项目,并且没有时间去重构已经存在的代码,那么可以考虑显式的指定名称,而不依赖自动命名:
@task(name='proj.tasks.add')
def add(x, y):
return x + y
上下文
request包含了与正在执行的任务相关的信息和状态。
request定义了下面的属性:
id :正在执行的任务的唯一的id
group:如果这个任务是一个组的成员,那么这个属性的值是组的唯一id
chord:这个任务所属的chord的唯一的id
args:位置参数
kwargs:关键字参数
reties:当前任务已经被重试了多少次,它是一个从0开始的整型
is_eager:如果任务在客户端本地执行,而不是由worker执行,那么设置为True
eta:任务的原始的ETA(estimated time of arrival),它是一个UTC时间(依赖于CELERY_ENABLE_UTC设置)
expires:任务的原始的失效时间。它是一个UTC时间(依赖于CELERY_ENABLE_UTC设置)
logfile:worker记录日志的文件
loglevel:当前使用的日志级别
hostname:正在执行任务的worker实例的主机名
delivery_info:额外的消息投递信息。它是一个包含用于投递这个任务的交换机和路由键的映射。比如,它可以被retry()使用,来重新发送任务到相同的目的队列。这个字典中可用的键依赖使用的消息队列服务
called_directly:如果任务不是被worker执行的,那么这个标记被设置为True
callbacks:如果任务成功返回,要调用的子任务的列表
errback:如果任务失败,要调用的子任务列表
utc:如果调用者启用了utc,会被设置为True
3.1中新增的
headers:消息头的映射(可能是None)
reply_to:向哪个队列发送回复
correlation_id:通常与taskid相同,在amqp中用来追踪(某个响应)是哪一个(请求的)回复
下面是一个在上下文中访问任务信息的例子:
@app.task(bind=True)
def dump_context(self, x, y):
print('Executing task id {0.id}, args: {0.args!r} kwargs: {0.kwargs!r}'.format(
self.request))
bind参数意味着:这个函数是一个“绑定”的方法。以便能够访问task类型实例上的属性和方法。
logging
worker会自动设置logging,或者也可以人工地设置logging。
可以使用一个叫做“celery.task”的logger,
参考资料