-encoding选项,指定源代码文件的编码-D选项,设置file.encoding属性,这个属性会作为reader、writer、String.getBytes()等操作的默认编码UTF-8UTF-16编码
UTF-16是双字节编码,Java的char也是双字节的UTF-16并不是固定占用2个字节,根据字符在unicode字符集中的位置,可能占用2个字节,也可能占用4个字节Code Point(中文名是:码位,它是一个数值)和字符之间的映射关系。比如,ASCII是一个字符集,字母a是ASCII字符集中的一个字符,字母a的Code Point是97。字符集中有多少个Code Point是由字符集规定的。比如unicode字符集是使用4个字节的数值来表示字符,因此unicode字符集有2的32次方个Code Point,但是并非所有的Code Point都被使用了。UTF-8、UTF-16、UTF-32都是unicode字符集的实现UTF-16编码的字符串本文是针对Python2x的
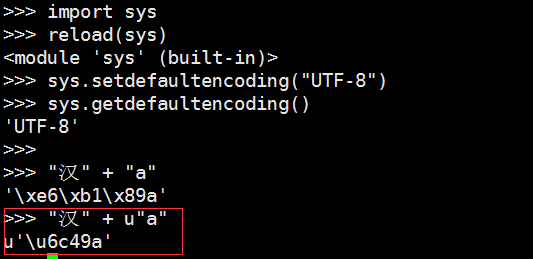
#coding: utf8之类的注释来指定>>> import sys >>> sys.getdefaultencoding() 'ascii'
>>> import sys >>> reload(sys)>>> sys.setdefaultencoding("UTF-8") >>> sys.getdefaultencoding() 'UTF-8'
需要特别注意的是,当混用str和unicode的时候,Python会尝试用默认的编码对str进行解码:
// filename: Main.java
public class Main {
public static void main(String[] args) throws Exception {
// javac会使用-encoding选项指定的或操作系统默认的字符编码对源代码进行解码
String string = "汉";
System.out.println("Internal:");
for (int ind=0; ind<string.length(); ++ind)
System.out.print(String.format("\t%x", (int)string.charAt(ind)));
System.out.print("\nUTF-8:\n\t");
byte[] bytes = string.getBytes("UTF-8");
for (byte b: bytes)
System.out.print(String.format("%1$x", b));
System.out.print("\nGBK:\n\t");
bytes = string.getBytes("GBK");
for (byte b: bytes)
System.out.print(String.format("%1$x", b));
}
}
IDEA的右下角可以指定源代码文件的字符编码:
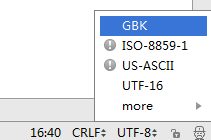
将上面的源代码文件的编码设置为UTF-8。
因为windows的默认编码是GBK,所以执行javac Main.java,编译源代码文件时,会报错:

可以通过-encoding命令行选项来指定源代码文件的编码:javac -encoding UTF-8 Main.java。
执行编译后得到的class:
java Main
输出如下:
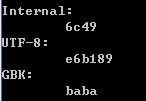
可见:unicode字符“汉”在JVM内部被存储为6C49,对应的UTF-8字节序列是E6 B1 89,对应的GBK字节序列是BA BA。
public class Main {
public static void main(String[] args) throws Exception {
byte[] bytes = new byte[]{-26, -79, -119};
System.out.println("file.encoding=" + System.getProperty("file.encoding"));
System.out.println(new String(bytes));
}
}
编译:
javac Main.java
执行:
java Main
输出如下:
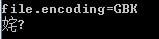
使用GBK编码给UTF-8字节序列解码的时候,会出乱码。可以通过-Dfile.encoding=xxx的方式指定默认编码:
java -Dfile.encoding=UTF-8 Main
输出如下:
