gearman是一个通用的应用程序框架,用来在机器或进程之间分发任务。它支持并发的执行任务,负载均衡处理,和多语言系统集成。gearman能够应用的领域非常广泛,比如:高可用的网站、数据库复制事件的传输等。
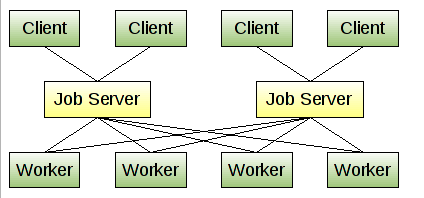
gearman的请求处理过程涉及三个角色:client -> jobserver -> worker:
clientjobserverworkergearman的工作原理图如下:

从上图可以看出,client api、jobserver、worker api都是gearman本身提供的,并且client api和worker api都很丰富。开发者只需要实现client应用程序和worker应用程序。
--hashtable-buckets arg (=991)选项来修改桶的数量),最多可存储3M个任务,如果队列中任务的数量超过了300万,那么应该使用更多的哈希桶(991 * job的数量 / 3M),比如说为了容纳2^32个任务,那么应该将--hashtable-buckets arg (=991)设置为1733003,这会额外消耗大约26M的内存。队列中的任务数不能超过2^32个。
后台任务时序图:
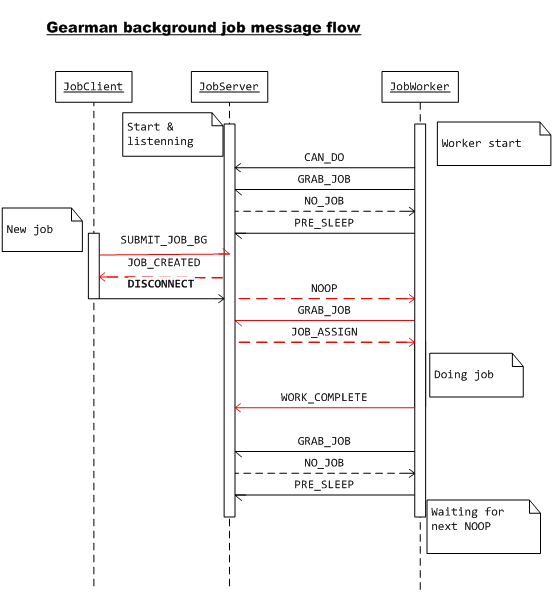
client提交完任务,jobserver成功接收并返回给client JOB_CREATED消息之后,client就断开与jobserver之间的连接了。在后台任务中,client是无法从jobserver中获取到任务的执行结果的。
一般工作任务时序图:
client在job执行的整个过程中,与jobserver都是保持连接的,因此,在一般的工作任务中,client是可以从jobserver中获取到任务的执行结果的。
同时,client端还可以发起job status的查询。当然,这需要worker端的支持。(后面会有一个python的例子)
CAN_DO消息,注册到jobserver上。
GRAB_JOB,主动要求分派任务。
NO_JOB。
NO_JOB后,进入空闲状态,并给jobserver返回PRE_SLEEP消息,告诉jobserver:“如果有工作来的话,先用NOOP请求我。”
PRE_SLEEP消息后,知道了发送这条消息的worker已经进入了空闲态。
NOOP消息。
NOOP消息后,发送GRAB_JOB向jobserver请求任务。
WORK_COMPLETE给jobserver。
wget http://ftp.gnu.org/gnu/gperf/gperf-3.0.4.tar.gz tar zxvf gperf-3.0.4.tar.gz cd gperf-3.0.4 ./configure && make && sudo make install
sudo yum install -y libevent-devel
sudo yum install -y libuuid-devel
1.1.12 release。
tar zxvf gearmand-1.1.12.tar.gz
cd gearmand-1.1.12
./configure
make && sudo make install
常见问题:
boost>=1.39,可能是没安装gcc-c++,有的机器可能安装了gcc,但是没有安装gcc-c++,可使用命令:yum install gcc-c++来安装。
000000 [ main ] socket()(Address family not supported by protocol) -> libgearman-server/gearmand.cc:470错误,解决办法是启动时,添加参数-L <your ip>,限定只绑定ipv4地址,忽略ipv6。
gearmand -L 127.0.0.1 -p 4730 -r http --http-port 8080 --verbose DEBUG -d -l gearman.log -P gearman.pid -R -w 10
"""
gm_worker.py
"""
import time
import gearman
gm_worker = gearman.GearmanWorker(['127.0.0.1:4730'])
def task_listener_reverse_inflight(gearman_worker, gearman_job):
reversed_data = list(reversed(gearman_job.data))
total_chars = len(reversed_data)
for idx, character in enumerate(reversed_data):
gearman_worker.send_job_data(gearman_job, str(character))
gearman_worker.send_job_status(gearman_job, idx + 1, total_chars)
time.sleep(0.1)
return 'successful'
gm_worker.register_task('reverse', task_listener_reverse_inflight)
gm_worker.work()
"""
gm_client.py
"""
import time
from gearman import GearmanClient
gearman_client = GearmanClient(['127.0.0.1:4730'])
gearman_request = gearman_client.submit_job('reverse', 'test gearman', wait_until_complete=False, background=False)
while gearman_client.get_job_status(gearman_request).state != 'COMPLETE':
time.sleep(0.2)
print 'status:', gearman_request.status
print 'data:', gearman_request.data_updates
print '\n'
python gm_worker.py & python gm_client.py
client应用程序会在标准输出打印类似的信息:
$python gm_client.py
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 0, 'numerator': 0, 'running': False, 'known': True, 'time_received': 1447068562.876595}
data: deque([])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 2, 'running': True, 'known': True, 'time_received': 1447068563.077448}
data: deque(['n', 'a'])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 4, 'running': True, 'known': True, 'time_received': 1447068563.278444}
data: deque(['n', 'a', 'm', 'r'])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 6, 'running': True, 'known': True, 'time_received': 1447068563.479357}
data: deque(['n', 'a', 'm', 'r', 'a', 'e'])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 8, 'running': True, 'known': True, 'time_received': 1447068563.680194}
data: deque(['n', 'a', 'm', 'r', 'a', 'e', 'g', ' '])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 10, 'running': True, 'known': True, 'time_received': 1447068563.881131}
data: deque(['n', 'a', 'm', 'r', 'a', 'e', 'g', ' ', 't', 's'])
status: {'handle': 'H:e010125026018.bja:14', 'denominator': 12, 'numerator': 12, 'running': True, 'known': True, 'time_received': 1447068564.082074}
data: deque(['n', 'a', 'm', 'r', 'a', 'e', 'g', ' ', 't', 's', 'e', 't'])
在非后台任务中,gearman支持在任务真正完成之前,就向客户端发送数据或更新job status,gearman client使用一些队列来追踪,何时收到了哪些特定的更新。
这个例子就展示了,在非后台任务中,client端如何对job status进行查询。尤其需要注意gm_worker.py的编写,和gm_client.py中发起任务请求时设置的wait_until_complete和background参数。
$gearadmin --help Options: --help Options related to the program. -h [ --host ] arg (=localhost) Connect to the host -p [ --port ] arg (=4730) Port number or service to use for connection --server-version Fetch the version number for the server. --server-verbose Fetch the verbose setting for the server. --create-function arg Create the function from the server. --cancel-job arg Remove a given job from the server's queue --drop-function arg Drop the function from the server. --show-unique-jobs Show unique jobs on server. --show-jobs Show all jobs on the server. --getpid Get Process ID for the server. --status Status for the server. --workers Workers for the server. --shutdown Shutdown server. -S [ --ssl ] Enable SSL connections.
telnet直接连接到gearmand,查看jobserver状态:
[root@iZ23dastruaZ ~]# telnet 127.0.0.1 4730 Trying 127.0.0.1... Connected to 127.0.0.1. Escape character is '^]'. workers #显示连接的worker及注册的函数 31 127.0.0.1 - : 32 127.0.0.1 - : echo echo2 . status #Function Name,Jobs in queue,Jobs running,Workers registered echo2 0 0 1 echo 0 0 1 . maxqueue echo 1000 #限制某个函数在队列中的最大任务数,第三个参数是可省的,表示不限制 OK version #jobserver的版本 OK 1.1.12 shutdown graceful #graceful代表优雅关闭,否则强制关闭。 OK verbose #log级别 OK DEBUG
admin_clientgearman admin_client为例:
""" python_gearman_admin_client.py """ import gearman gm_admin_client = gearman.GearmanAdminClient(['localhost:4730']) print gm_admin_client.get_status() print gm_admin_client.get_version() print gm_admin_client.get_workers() print gm_admin_client.ping_server()
输出结果:
({'workers': 1, 'running': 0, 'task': 'echo2', 'queued': 0}, {'workers': 1, 'running': 0, 'task': 'echo', 'queued': 0})
OK 1.1.12
({'file_descriptor': '31', 'tasks': ('echo', 'echo2'), 'client_id': '-', 'ip': '127.0.0.1'}, {'file_descriptor': '32', 'tasks': (), 'client_id': '-', 'ip': '127.0.0.1'})
0.000275850296021
在gearman jobserver内部,job是存储在内存的哈希表中的,这意味着一旦jobserver重启或崩溃,未被执行的job会丢失。
持久化队列是指:将job放到内部队列之前,jobserver会调用一个模块回调函数,用某种持久化的方式存储job,以便在jobserver崩溃或重启的时候,job可以在稍后重新执行。
在job被worker成功执行之后,(jobserver)会调用另外一个模块回调函数,从持久化存储中,删除这个job。
对于一个job来说,如果在这两个回调函数之间,jobserver崩溃或重启了,当下一个jobserver启动的时候,这个job会被重新加载。
当jobserver启动的时候,它会调用replay函数,这个回调函数会返回所有未完成的job的列表。jobserver会把这些job放进内存队列。当replay完成的时候,jobserver也就完成了它的初始化,此时所有的job都是可运行的(队列的状态应该是与jobserver崩溃时是一样的)。当这些任务被执行完成的时候,它们会被(从持久化队列中)删除。
TIP: 持久化队列只对后台job有效,因为前台job依附于客户端,如果jobserver崩溃了,客户端将会从其它地方重新启动这个前台job或者返回错误。而后台job没有依附于客户端,如果要想让它在jobserver崩溃后重新执行,则需要持久化队列。
Note:持久化必然影响高性能。
使用mysql作为gearman的持久化队列
create database gearman; create table `gearman_queue` ( `unique_key` varchar(64) NOT NULL, `function_name` varchar(255) NOT NULL, `priority` int(11) NOT NULL, `data` LONGBLOB NOT NULL, `when_to_run` INT, PRIMARY KEY (`unique_key`) );
-q [ --queue-type ] arg (=builtin):要使用的持久化队列类型,此时应该设置为mysql
--mysql-host arg (=localhost):MySQL服务器监听的主机名或ip地址
--mysql-port arg (=3306):MySQL服务器监听的端口,默认是3306
--mysql-user arg:MySQL的用户名
--mysql-password arg:MySQL的用户的密码
--mysql-db arg:存储job的MySQL库名称
--mysql-table arg (=gearman_queue):存储job的MySQL表名称
从典型部署结构可以看出,jobserver之间是没有连接的,也就是jobserver间是不共享background job的。如果通过让多个jobserver指向同一个持久化队列,是否可以实现的jobserver的互相备份呢?答案是否定的,因为jobserver只有在启动时才会将持久化队列中的background job转入到内存队列,也就是说,jobserver1如果宕机且永远不启动,jobserver2一直正常运行,那么在jobserver1宕机前被提交到它的未被执行的background job将永远都待在持久化队列中,得不到执行。另外如果多个job server实例指向同一个持久化队列,同时重启多个jobserver实例会导致持久化队列中的工作任务被多次载入,从而导致消息重复处理。
一个建议的部署架构
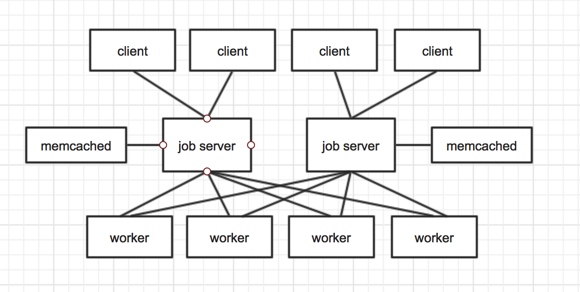
在这种部署架构下,需要对jobserver进行监控,在jobserver异常退出之后,进行重启,最大化的保证了jobserver的高可用。
-t选项指定多个I/O线程,在jobserver内部有三种类型的线程:
-t选项的默认值是4,-t 0意味着gearmand尝试猜测它所能够使用的最大I/O线程的数量。
监听和管理线程主要负责接受新的连接,并把这些连接分派给I/O线程。它也会协调jobserver的启动和关闭。这个线程会使用一个libevent的实例来管理socket事件和内部管道上的信号。这个管道用于唤醒线程或协调关闭。
I/O线程负责socket上的读写系统调用和最初的包解析。当包被解析完成的时候,它会被放到一个(给处理线程使用的)内部队列(每个线程都有它自己的队列,因此只有非常少的连接)。每个I/O线程都使用它自己的libevent实例管理socket事件和内部管道上的信号。
处理线程内部应该没有系统调用,它负责管理许多列表和用于追踪唯一的key的哈希表,任务操作,函数,和任务队列。所有需要发送回连接的包都会被放进一个用于I/O线程的异步队列,I/O线程会取出这些数据包,并把他们发回被连接的socket。所有的包都会通过处理线程,因为它包含处理数据包所需要的信息。由于列表和哈希表复杂的“天性”,如果多个线程修改它们,那么过度的锁会导致性能可能比单线程还差(同时也会使代码复杂化)。未来更多的工作会交给I/O线程处理,处理线程只会保留管理哈希表和列表这些极少的功能。到目前为止还没有发现瓶颈,一个16核的Intel机器每秒能处理超过50K个任务。
为了保证在多线程的情况下生成的UUID的唯一性,那么应该运行uuidd守护进程。
sudo yum install -y uuidd service uuidd restart
ulimit -n来查看当前的限制:
$ulimit -n 4096
当fd用光之后,worker和client就会出现连接超时或无响应等异常情况。因此当发生类似情况时,应该首先检查/proc/[PID]/fd目录下文件描述符的数量,是否达到了ulimit -n的限制,并根据需要进行调整(请参考Linux increase the maximum number of open files or file descriptors)。
启动gearmand时可以通过-f [ --file-descriptors ] arg选项来设置gearmand进程的最大文件描述符数量,但是非特权用户不能设置soft limit的值。
-f [ --file-descriptors ] arg Number of file descriptors to allow for the process (total connections will be slightly less). Default is max allowed for user.
轮询调度
默认情况下,gearmand按照函数被worker注册的顺序,给每个worker连接分配任务。可以通过开启-R [ --round-robin ]选项,使gearmand按照round-robin 模式给worker连接分派任务,避免工作过于集中在某些设备上。
受限唤醒
通过-w [ --worker-wakeup ] arg (=0)选项,可以指定gearmand在收到任务时,唤醒多少个worker来处理,避免在worker数量非常大时,发送大量不必要的NOOP报文,试图唤醒所有的worker。
根据gearman协议设计,worker 如果发现队列中没有任务需要处理,可以通过发送PRE_SLEEP命令给gearmand,告知gearmand自己将进入睡眠状态。在这个状态下,worker不会再去主动抓取任务,只有服务器发送NOOP命令唤醒后,才会恢复正常的任务抓取和处理流程。因此gearmand在收到任务时,会去尝试唤醒足够的worker来抓取任务;此时如果worker的总数超过可能的任务数,则有可能产生惊群效应。
HTTP协议插件可以把HTTP请求映射成gearman任务,当前它只提供了客户端任务提交,但是将来它可能会被扩展成支持其他的请求类型。这个插件既能处理get请求,也能处理post请求,后者可以用来给jobserver发送一个workload,被请求的URL会被转换成被调用的函数。
比如,下面的这个请求:
POST /reverse HTTP/1.1 Content-Length: 12 Hello world!
它会被转换成一个任务提交请求:调用的函数是reverse,workload是Hello world!,响应是:
HTTP/1.0 200 OK X-Gearman-Job-Handle: H:lap:4 Content-Length: 12 Server: Gearman/0.8 !dlrow olleH
可以传递下面的请求头,来改变任务的行为:
比如说,想要运行一个低优先级的后台任务,可以发送下面的请求:
POST /reverse HTTP/1.1 Content-Length: 12 X-Gearman-Background: true X-Gearman-Priority: low Hello world!
这个请求的响应,不会有任何相关的数据,因为它是一个后台任务:
HTTP/1.0 200 OK X-Gearman-Job-Handle: H:lap:6 Content-Length: 0 Server: Gearman/0.8
!!!http协议应该被认为是实验性的!!!
TIPS: 我在最新的release版本1.1.12中,对http协议插件进行测试的结果是: 1,该插件确实既支持get请求,也支持post请求,并且post请求可以给jobserver传递workload。 2,当传递`X-Gearman-Background: true`请求头的时候,客户端会阻塞,无法获取到响应。换言之:在该版本中,并不支持后台任务! 3,当调用前台任务的时候,并不能通过响应的body中获取到任务的执行结果,因为响应的body是空的,同时`Content-Length`的值是`0`。但是`X-Gearman-Command: WORK_COMPLETE`表明任务已经成功执行完成了。 之后在0.8版本中,对http协议插件进行测试,测试的效果与官网描述的一致。
gearman不支持把失败的job重新放回队列,当任务在执行过程中出现异常,它只是将这个任务标记为“失败”,不会重新派发给其他的worker。这在worker遇到某些可恢复的错误,需要重试的情况下,是非常不友好的。下面是我总结的两个解决方案,可供参考:
-j [ --job-retries ] arg (=0)选项设置:在jobserver移除这个job之前,允许的最大重试次数。所以使用这种方式重试的话,那么需要做的是:
gearmand的时候,给-j [ --job-retries ] arg (=0)选项设置一个合理的值。
on_job_exception(self, current_job, exc_info)),可以在这个回调函数中,重新发送相同的任务。但是需要自己控制重试次数。